1. 들어가며
지난 주말 솝트에서 진행하는 해커톤에 참여했다.
결과로 대상을 타기는 했지만 개인적으로 아쉬웠던 부분이 있어 기록 및 학습을 하려고 한다.
이번 해커톤에서 가장 부끄러웠던 건 결과물이 아니라 내 코드에 대한 내 이해의 깊이였다.
이번에 구현하게 된 서비스는 매일 나의 실수를 하나씩 기록하고 이거에 대한 회고를 추후 기록하는 서비스였다.
그 안에 이미지 업로드 요구사항이 있었고, 그건 이 서비스의 핵심 기능이었다. 나는 그 핵심을 클라이언트가 Presigned URL로 NCP에 직접 업로드하고 서버는 검증만 하는 방식으로 설계했다. 검증이 끝난 객체는 public-read로 열고 카드에는 공개 URL을 저장하는 식이었다. 흐름 자체는 문제 없이 흘러갔고 검증 단계도 분리해뒀고 public/private 트레이드오프도 의식적으로 골랐다.
사실 문제는 ‘동작한다’는 것 너머에 있었다.
나는 이전에 S3로 내부에 있는 이미지에 대한 Presigned URL로 조회하는 GET API를 만들어본 적은 있다. 그런데 이미지를 업로드하는 API를 만든 건 이번이 처음이었다. 하지만 그것은 웹 대상 서비스였고 이번엔 앱이라는 차이가 있었다. 거기에 더해 이번에는 AWS가 아니라 NCP였다. AWS는 비용 부담 때문에 후보에서 빠졌고 자리에서 팀원과 NCP관련 문서를 보다가 “NCP Object Storage가 S3 호환을 공식 지원한다” 는 문장을 발견하고 AWS SDK 그대로 쓰면 될 것 같다는 결론을 내렸다.
코드는 동작했다. 그런데 솔직히 말해서 나는 그때 내가 작성한 코드의 절반쯤은 “왜 그렇게 써야 하는지”를 정확히는 모르고 있었다.
각각의 코드에 대해 “이게 없으면 어떻게 깨지는지”를 한 문장으로 설명해보라고 하면 제대로 설명하지 못한다. SDK 예제와 블로그 글, AI 생성 결과를 짜깁기해서 동작하게 만든 코드였지 내가 책임지는 코드는 아니었다.
그게 협업에서 드러난 순간이 마지막 발표 직전이었다. 발표를 위한 시연 영상을 찍어야 했는데 이미지 업로드 요청이 3분 넘게 걸렸다. Presigned URL 발급이 느린 건지 클라이언트가 PUT 하는 단계가 느린 건지, 검증 단계가 느린 건지 정확히 어디서 시간이 갔는지조차 그 자리에서 정확하게 파악해내지 못했다. 결국 그 자리에서는 “와이파이가 너무 안 좋아서 그런 거 같다”로 닫고 넘어갔다.
지금 다시 보면 그 결론은 절반은 맞고 절반은 게으른 판단이었다. 와이파이가 안 좋은 건 사실이지만 같은 사진을 같은 와이파이에서 더 빠르게 올릴 수 있는 방법이 있었다. 그걸 그 자리에서 짚지 못했던 건 와이파이의 문제가 아닌 내 기본기의 문제였다.
이 글은 그래서 선택의 글이 아니라 자각의 글이다. “왜 이걸 골랐는가”가 아니라 “그 선택을 내릴 만큼 내가 알고 있었는가와 내가 뭐를 몰랐던 것이었는가”를 적어보려고 한다.
---
2. 이번에 구현했던 흐름
이 장에서는 내가 실제로 만든 흐름을 을 먼저 정리해보려 한다.
2.1 왜 클라 직접 업로드(Presigned URL) 방식인가
선택지는 사실상 두 가지였다.
- 서버 경유 업로드 — 클라가
multipart/form-data로 서버에 파일을 보내고 서버가 받아 NCP에 PUT 한다. - 클라 직접 업로드 (Presigned URL) — 서버는 업로드 URL만 발급하고 클라가 그 URL에 직접 PUT 한다. 업로드가 끝나면 서버에 “다 올렸다”고 알려서 검증 받는다.
두 방식의 트레이드오프는 명확했다.
서버 경유의 장점은 단순함이다. 클라는 POST /v1/mistakes에 이미지를 통째로 실어 보내면 되고 서버는 MIME/사이즈 검증과 카드 작성을 한 트랜잭션 안에서 끝낼 수 있다. 스토리지 자격증명이 외부에 새지 않고 실패 시 정리도 쉽다. 대신 단점은 서버가 모든 이미지 트래픽의 중계자가 된다는 것이다. 10MB 이미지가 매번 서버 메모리/네트워크를 한 번 더 거치고 업로드 동안 톰캣 워커 스레드가 잡혀 있다. 모바일에서 큰 이미지를 보내면 “서버까지 PUT → 서버가 다시 NCP로 PUT”의 두 번 업로드가 되어 체감 속도도 느려진다.
Presigned 방식의 장점은 정확히 반대다. 서버는 이미지 바이트를 단 한 번도 만지지 않는다. 트래픽은 클라 ↔ NCP 사이에서만 흐른다. 워커 스레드가 업로드 시간만큼 잡히지 않고 모바일은 한 번만 업로드하면 된다. 대신 흐름이 4단계로 길어지고(presign → 클라 PUT → complete → mistakes), 검증 시점이 PUT 이후로 미뤄지고, 정합성에 빈틈이 생긴다(고아 객체).
이 트레이드오프를 알고 나서 결정의 근거는 세 가지였다.
(1) 서비스 특성상 이미지가 무조건 들어온다.
실수 카드는 “사진 + 글”이지 글만 쓰는 일기장이 아니다. 즉 카드 작성 = 이미지 업로드라고 봐도 무방하다. 핵심 경로가 모두 서버를 경유한다면 사용자가 조금만 모여도 서버가 가장 먼저 흔들릴 게 뻔했다. 가장 자주 일어나는 동작은 서버 부담이 가장 적은 형태여야 했다.
(2) 해커톤이라는 짧은 호흡과 어울렸다.
역설적으로 “흐름이 복잡해진다”는 단점이 우리에겐 큰 문제가 아니라고 생각했다. 클라와 서버가 한 공간에 있고 한 번 합의해두면 된다고 생각했다. 일반적인 SaaS였다면 클라-서버 간 소통 비용이 있었겠지만 우리에겐 그 비용이 작았다. 구현 및 이후 동작에서 생길 수 있는 문제를 고려하는 것보다 Presigned 방식으로 구현하고 클라 구현 가이드 문서를 따로 만들어 전달드리는 방식의 비용이 훨씬 싸다고 판단했다.
(3) 정합성 문제는 complete 단계를 두는 것으로 풀 수 있었다.
“검증이 PUT 이후로 미뤄진다”는 단점은 complete를 명시적으로 두어서 막는다. 클라가 업로드를 끝낸 뒤 서버에 objectKey + 예상 contentType + 예상 contentLength를 보내면 서버가 NCP에 가서 객체가 실제로 올라왔는지 크기와 MIME이 클라 주장과 일치하는지 확인한다. 불일치하면 그 자리에서 객체를 삭제한다. “올라온 척”을 막는 게이트를 명시적으로 두는 방향으로 생각했다.
2.2 4단계 흐름
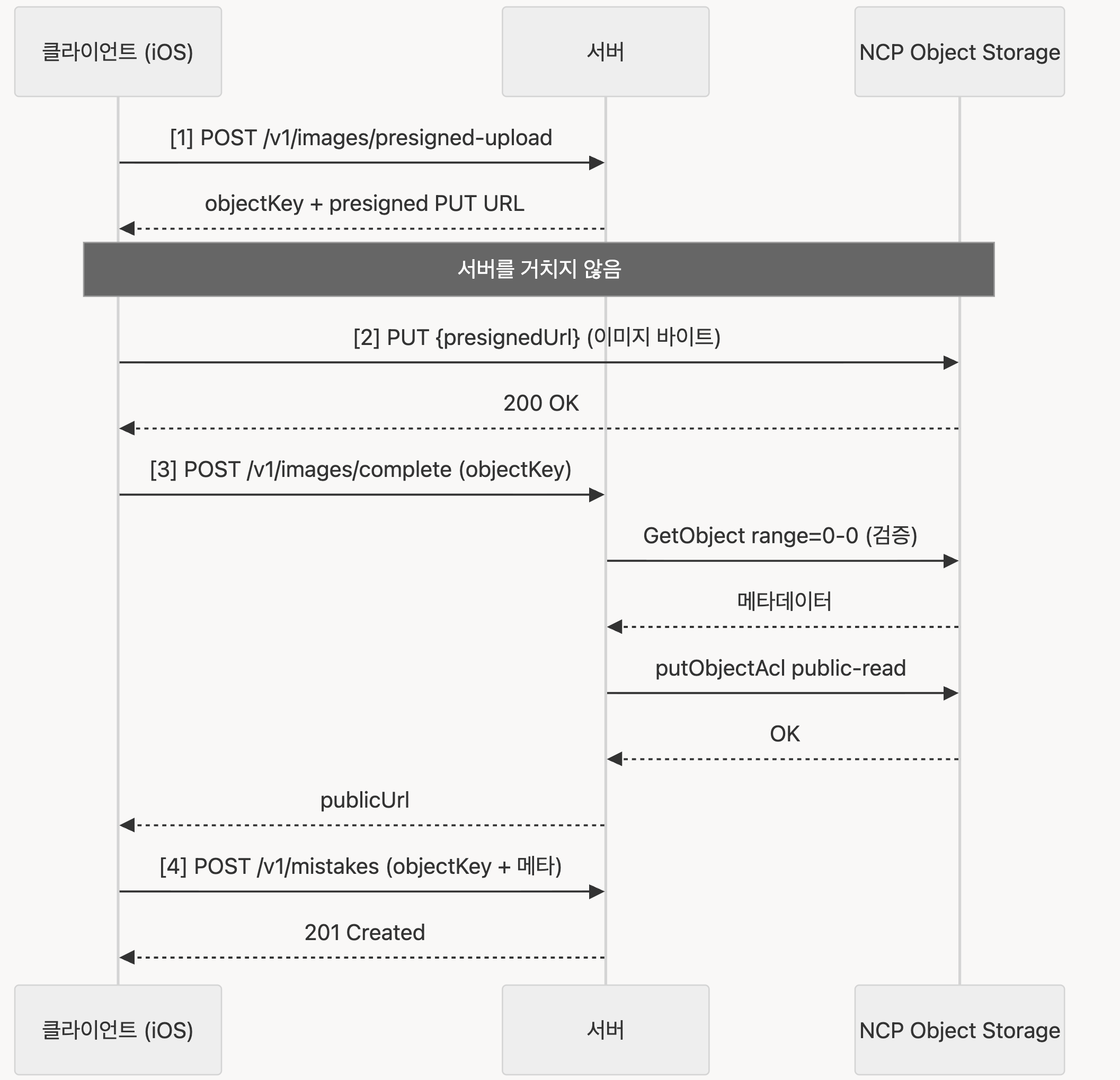
/v1/images/presigned-upload, /v1/images/complete 두 엔드포인트가 스토리지 책임을 담당하고 그 사이에 클라이언트가 NCP와 서버를 거치지 않고 직접 통신하는 PUT이 끼어 있다. 카드 생성 API는 그 결과 objectKey 한 줄만 받는다.
2.3 NCP를 S3 SDK로 다루기 위한 설정
NCP에 AWS SDK를 붙이기 위한 ObjectStorageConfig는 이렇게 구현돼있다.
S3Client.builder()
// SDK가 기본적으로 가려는 https://s3.{region}.amazonaws.com 을 NCP 호스트로 덮어씀.
// 이 줄이 빠지면 SDK는 AWS S3로 요청을 보낸다.
.endpointOverride(URI.create(properties.endpoint())) // https://kr.object.ncloudstorage.com
// region은 '통신할 호스트'가 아니라 'SigV4 서명에 들어가는 라벨'.
// NCP가 자기 region을 "kr-standard"로 정해뒀기 때문에 서명도 같은 문자열을 써야 검증을 통과한다.
// 통신 호스트는 위 endpointOverride에서 이미 결정됨.
.region(Region.of(properties.region())) // kr-standard
// AccessKey + SecretKey를 코드(설정)에서 직접 주입. 운영환경이면 IAM 역할/Secrets Manager 등으로 빼야 한다.
.credentialsProvider(credentialsProvider(properties))
.serviceConfiguration(S3Configuration.builder()
// 버킷을 호스트 서브도메인({bucket}.host)이 아니라 경로(host/{bucket}/{key})로 붙인다.
// NCP는 path-style이 기본이다. false로 두면 {bucket}.kr.object.ncloudstorage.com 같은 호스트를 만들려고 해서 DNS에서 깨진다.
.pathStyleAccessEnabled(true)
.build())
.build();지금 다시 보면 세 줄이 “S3가 아닌 곳에 S3 SDK를 연결한다”의 본체다.
endpointOverride— SDK가 기본적으로https://s3.{region}.amazonaws.com으로 가는 걸 막고 NCP 호스트로 돌려준다.pathStyleAccessEnabled(true)— 버킷을 호스트 서브도메인({bucket}.s3.amazonaws.com)이 아니라 경로(/{bucket}/{key}) 로 붙이게 한다. NCP는 path-style을 기본으로 받는다.Region.of("kr-standard")— NCP가 정한 리전 이름이다.
이 세 줄 각각이 정확히 무엇을 바꾸는지는 3장에서 다시 보고. 여기서는 “이 세 줄이 빠지면 SDK는 AWS S3로 가려고 한다”는 정도만 정리해보려 한다.
S3Presigner도 똑같이 한 번 더 만든다. 한 클라이언트로 둘 다 하면 좋겠다고 생각했지만 v2 SDK에서는 S3Presigner가 별도 빌더라 어쩔 수 없다.
2.4 [1단계] Presigned URL 발급
public PresignedUploadUrlResponse generateUploadUrl(PresignedUploadUrlRequest request) {
// 클라에서 보낸 contentType/contentLength가 허용 범위인지 사전 검증 (MIME 화이트리스트 + 최대 크기)
validateUploadRequest(request);
// "image/JPEG ", "image/jpeg" 등 표기 정규화 (lowercase + trim)
String normalizedContentType = normalizeContentType(request.contentType());
// {prefix}/{yyyy}/{MM}/{dd}/{UUID}.{ext} 형태로 키 생성 — 추측 불가능 + 날짜 prefix로 사후 정리 용이
String objectKey = generateObjectKey(normalizedContentType);
// PUT 대상이 될 객체의 정체(bucket + key)를 묶음.
// 주의: .contentType(...)을 일부러 안 넣었음 → Content-Type이 서명에 묶이지 않음 → 클라가 어떤 헤더로 PUT 하든 서명은 통과
PutObjectRequest putObjectRequest = PutObjectRequest.builder()
.bucket(properties.bucket())
.key(objectKey)
.build();
// presign 요청을 만든다. signatureDuration = URL 유효시간 (현재 10분)
PutObjectPresignRequest presignRequest = PutObjectPresignRequest.builder()
.signatureDuration(properties.uploadUrlExpiration())
.putObjectRequest(putObjectRequest)
.build();
// 여기는 네트워크 호출이 아님. SecretKey로 로컬에서 SigV4 서명만 만들어 URL을 합성하는 연산.
// → NCP에 흔적 남지 않음. 발급은 본질적으로 빠름.
PresignedPutObjectRequest presignedRequest = s3Presigner.presignPutObject(presignRequest);
return new PresignedUploadUrlResponse(
objectKey, // 클라가 [3단계] complete / [4단계] mistakes 에 다시 들고 와야 할 키
presignedRequest.url().toString(), // 클라가 [2단계]에서 PUT 할 대상 URL
properties.uploadUrlExpiration().toSeconds(), // URL 유효시간(초)
Map.of("Content-Type", normalizedContentType) // "이 헤더로 PUT 해주세요" 라는 권유 (서명에 묶이지 않아 강제는 아님)
);
}이 코드 안에 구현된 선택들
(1) objectKey 포맷{prefix}/{yyyy}/{MM}/{dd}/{UUID}.{ext} 형태로 키를 만든다.
지금 보면 이 키 포맷은 두 가지 효과를 낸다. 첫째, UUID 부분이 추측 불가능해서 “URL을 모르면 못 본다”는 가정이 어느 정도 성립한다. 둘째, 날짜 prefix를 깔아두면 나중에 정리 배치를 돌리거나 사고가 났을 때 “특정 날짜 이전 객체만 골라낸다”가 prefix 매칭으로 끝난다.
(2) Content-Type을 검증은 하되 서명에는 안 묶었다
PutObjectRequest.builder().bucket().key().build() — .contentType(...)이 빠져 있다. 즉 클라이언트가 PUT 할 때 어떤 Content-Type을 보내든 서명은 통과한다.
응답에 Map.of("Content-Type", normalizedContentType)을 같이 내려주긴 했지만 이건 클라에 보내는 “이 헤더로 PUT 하세요”라는 권유일 뿐 서버가 강제하는 건 아니다.
지금 보면 이건 의식적 결정이라기보다는 그 자리에서 ‘서명 불일치로 PUT이 깨질 가능성’을 막아두는 자가안전장치에 가까웠다. SDK 예제에서 .contentType(...)을 안 묶은 형태를 그대로 가져온 것이기도 하다. 그 대신 진짜 검증은 [3단계] complete에서 객체의 실제 메타데이터를 가지고 한다. 정합성을 발급-시점이 아니라 검증-시점으로 미루는 선택이다.
(3장에서 다시 보겠지만 이 결정은 양면이 있다. 클라 코드가 헤더를 잘못 보내도 PUT은 성공하지만 그 대신 NCP가 객체의 Content-Type을 클라이언트가 보낸 헤더 그대로 저장하기 때문에 검증 단계에서 “클라가 보낸 헤더” vs “request body의 contentType”이 어긋날 여지가 생긴다. 이번에는 그 갭이 우연히 잘 맞아서 안 터졌다.)
(3) 만료시간 10분uploadUrlExpiration: 10m. PUT 한 번에 10분은 보수적으로 봐도 길다. 모바일이 PUT 한 번 하는 데 그렇게 긴 시간이 필요하지는 않다.
2.5 [2단계] 클라이언트가 NCP에 직접 PUT
이건 서버 코드에 안 잡힌다. 클라가 1단계에서 받은 URL로 PUT을 쏜다. 서버는 이 단계 동안 어떤 일도 하지 않는다.
이게 이 아키텍처의 핵심 이점인데 동시에 트러블슈팅을 어렵게 만든 지점이기도 하다. 서버 로그에는 이 구간의 흔적이 전혀 없다. 무엇이 얼마나 걸렸는지 알려면 클라이언트가 알려줘야 한다.
2.6 [3단계] complete — 검증 + ACL 전환
// GetObject + Range: bytes=0-0 → 본문은 1바이트만 받고 메타데이터(Content-Type / Content-Range)를 챙긴다.
// 정석은 HeadObject (본문 없이 메타만). 여기서는 GetObject로 갔고 다음에 구현한다면 HeadObject가 맞다.
// try-with-resources로 응답 스트림을 명시적으로 닫아준다 — 안 닫으면 SDK 커넥션 풀이 누수됨.
try (ResponseInputStream<GetObjectResponse> objectStream = s3Client.getObject(GetObjectRequest.builder()
.bucket(properties.bucket())
.key(request.objectKey())
.range("bytes=0-0") // 0~0번째 바이트 (즉 1바이트만). 응답은 206 Partial Content
.build())) {
GetObjectResponse response = objectStream.response();
// 클라가 주장한 contentType/contentLength가 실제 업로드된 객체의 메타데이터와 일치하는지 검증.
// contentLength는 response.contentLength()(=1)가 아니라 Content-Range 헤더의 "/뒤" 숫자를 파싱해야 함.
// 불일치/사이즈 초과면 BaseException을 던지고, 상위 catch에서 객체를 삭제한다.
validateUploadedObject(request, response);
}
// 검증을 통과한 객체에만 ACL을 PUBLIC_READ로 박는다.
// 버킷 단위 public이 아니라 객체 단위 — 검증 통과 전의 객체는 절대 노출되지 않음.
makeObjectPublic(request.objectKey());이 단계에서 한 결정 두 가지.
(1) HEAD가 아니라 GetObject + range("bytes=0-0")
“객체가 존재하는지 + Content-Type / Content-Length가 무엇인지”만 알고 싶다면 HeadObject를 사용해야 하는게 맞다. 그런데 나는 GetObject + 1바이트 range로 갔다. 이유는 솔직히 그 자리에서 HEAD/GET의 차이를 깊게 생각하지 않았고 “어차피 body는 첫 1바이트만 받으면 거의 0이니까” 정도였다. 결과적으로 동작했지만 이해를 하고 보면 한 번 부자연스러운 코드다.
추가로 Content-Length를 직접 신뢰하지 않고 Content-Range의 / 뒤 숫자를 파싱한다. range 응답에서 Content-Length는 “이번 응답이 돌려준 바이트 수(=1)“이지 “객체 전체 크기”가 아니기 때문이다.
(2) 검증 통과한 객체에만 ACL을 PUBLIC_READ로 변경한다 코드는 검증을 통과한 객체에만 ACL을 박는 방식으로 되어 있다. 이론적인 이점은 두 가지다. 첫째, 검증 통과 전의 객체가 잠깐이라도 노출될 여지가 없다. 둘째, 운영 중 정책을 좁히려 할 때 객체 단위로만 손대면 되니까 회복이 쉽다.
그런데 해커톤 컨텍스트에서는 이 두 이점이 거의 의미가 없었다. 더 명확하게는 NCP에 대한 이해가 없어 버킷 자체를 public으로 바꾸는 법을 몰라 객체를 public 방식으로 바꿔서 넣는 방법을 선택했다.
객체 키가 UUID라 검증 전 노출 시간(수 초)에 누가 그 키를 추측해 들어올 가능성은 사실상 0이고, “운영 중 정책 변경”은 해커톤에는 존재하지 않는 시나리오다. 오히려 그 비용으로 complete 단계가 NCP 왕복 2회(GetObject + putObjectAcl)가 됐다 4장에서 다루겠지만 트러블슈팅 시 의심해야 할 후보가 한 줄 늘었다는 뜻이다.
해커톤 단위로만 보면 버킷 자체를 public으로 한 번 열어두고 ACL 호출을 통째로 없애는 쪽이 더 단순하고 빠른 선택이었을 수 있다. 객체 단위 ACL을 고른 건 “더 안전해서”라기보다 SDK 예제를 그대로 따른 것에 가까웠다.
(다만 어느 쪽을 골랐든 한 가지는 똑같이 못 막는다 — 악의적 클라가 거짓 MIME으로 임의 파일을 PUT 해서 우리 NCP를 무료 파일 호스팅으로 쓰는 시나리오. complete 검증이 magic number까지 안 보기 때문이다. 이건 3.4의 “(4) 진짜 컨텐츠 검증”에서 다시 본다.)
검증 실패 시 객체를 즉시 삭제하는 것까지 한 메서드 안에서 같이 처리한다는 점은 객체 단위 ACL 방식과 무관하게 좋은 방향이었다.
2.7 정리
여기까지가 내가 구현한 흐름이다. 흐름은 굴러갔다. 다만 그 안의 선택들 중 “그 자리에서의 의식적 결정”은 일부였고 나머지는 SDK 예제와 그때그때의 직감으로 구현된 것들이었다. 다만 그 결정들 밑에 깔린 메커니즘 자체에 대한 이해는 얕았다. 그 얕음이 3장에서 메꿀 부분이고 4장에서 그 얕음이 결국 어떤 식으로 장애를 못 잡게 만들었는지를 알아보려 한다.
---
3. 학습 — 깔린 개념 다시 보기, 그리고 운영 환경이었다면
3.1 “S3 호환”이 실제로 보장하는 것
내가 NCP를 자리에서 골랐을 때 본 문장은 정확히 이거였다.
NCP Object Storage는 AWS S3 API와 호환된다.
이걸 본 순간 머릿속에서는 “AWS SDK를 그대로 쓸 수 있겠네”로 점프했다. 맞긴 한데 정확히 뭐가 호환되는지는 그때 깊이 보지 않았다. 다시 정리하면 “S3 호환”은 다음 세 가지의 약속이다.
(1) HTTP 요청/응답 형식이 S3와 같다. 버킷/객체에 대한 REST 인터페이스 — PUT /{bucket}/{key}, GET /{bucket}/{key}, HEAD /{bucket}/{key}, 그리고 ?acl, ?uploads 같은 서브리소스가 S3와 같은 모양으로 받아진다. 응답 XML 스키마도 마찬가지다.
(2) AWS Signature V4 인증을 받는다. Authorization 헤더의 시그니처 계산 방식이 AWS와 같다. 그래서 AWS SDK가 만드는 서명을 그대로 받아준다. (NCP는 V2도 받지만 V4가 기본이다.)
(3) 일부 S3 기능은 호환되지 않는다. 예를 들어 S3 Select, Object Lambda, Intelligent-Tiering, SSE-KMS 옵션 일부 등은 NCP가 지원하지 않거나 다르게 동작한다. “호환”은 “전체”가 아니라 “코어 객체 CRUD + 기본 ACL/Multipart” 정도라고 생각하는 게 안전하다.
내 코드에 있는 세 줄이 이 호환을 활용하는 방식이었다.
.endpointOverride(URI.create(properties.endpoint()))
.region(Region.of(properties.region()))
.serviceConfiguration(S3Configuration.builder().pathStyleAccessEnabled(true).build())- endpointOverride — SDK가 호스트를 결정하는 로직(
s3.{region}.amazonaws.com)을 통째로 덮어쓴다. 이 한 줄이 없으면 SDK는 AWS S3로 간다. - pathStyleAccessEnabled(true) — 버킷을 호스트의 서브도메인으로 붙일지(
{bucket}.s3.amazonaws.com) 경로로 붙일지(s3.amazonaws.com/{bucket})를 정한다. AWS는 둘 다 지원하지만(가상 호스팅 스타일이 기본), NCP는 path-style로 받는다. 이게 false면 SDK는{bucket}.kr.object.ncloudstorage.com같은 호스트를 만들려고 해서 DNS부터 깨진다. - Region.of(“kr-standard”) — 여기가 가장 헷갈렸던 부분이다. region은 사실 통신할 호스트를 정하는 값이 아니라 서명 문자열에 들어가는 라벨이다. SigV4의 “Credential Scope”에
{date}/{region}/s3/aws4_request형태로 들어간다. NCP가 자기 region 이름을kr-standard로 정해두었기 때문에 SDK가 만드는 서명도 같은 문자열을 써야 검증을 통과한다. endpoint를 override 한 시점에 통신 호스트는 이미 결정된 거고 region 값은 오직 서명을 위해 남는다.
솔직히 말하면 이 셋의 역할 분리 자체가 그때 내겐 떠오르지 않았다. region이 있으면 그냥 박는 것이고 endpoint가 있으면 그냥 박는 것이었다. 둘이 왜 둘 다 있어야 하는지를 의식하지 못했다는 게, “내가 짠 코드인데 왜 동작하는지 설명 못 한다”의 가장 작고 정확한 예시다.
왜 이 의문이 안 떠올랐는가를 다시 생각해보면, AWS S3를 정상적으로 쓸 때는 이 셋이 사실상 한 줄로 합쳐져 있기 때문이다.
// AWS S3 정공법
S3Client.builder()
.region(Region.US_EAST_1) // 이것만 있으면 됨
.build();endpointOverride가 없다. SDK가 region 값을 보고 알아서 s3.us-east-1.amazonaws.com 호스트를 만들어 준다. 여기서는 region이 “어디로 갈지”를 직접 결정한다. 그래서 region = 통신 대상이라는 직관이 자연스럽게 박힌다.
그 직관 위에 NCP 설정을 얹으면 이렇게 된다.
// NCP (S3 호환)
S3Client.builder()
.endpointOverride(URI.create("https://kr.object.ncloudstorage.com")) // 어디로 갈지를 명시
.region(Region.of("kr-standard")) // ???
.build();여기서 떠올랐어야 할 질문은 단순하다 — “endpoint로 어디로 갈지 이미 정했는데 region이 왜 또 필요해?” 그런데 SDK 예제는 둘 다 박아두라고 하니까, 의문 없이 그대로 박게 된다. 이게 “코드는 동작하지만 왜 그런지 모른다”가 시작되는 지점이다.
답을 알고 보면 이렇다. endpoint를 override 한 순간 region은 “어디로 갈지” 역할을 잃고 서명 라벨 역할만 남는다. SigV4 서명 계산 입력 중 하나인 Credential Scope 문자열 — {날짜}/{region}/s3/aws4_request — 에 그대로 들어가고, NCP 쪽에서도 같은 region 문자열로 서명을 다시 계산해서 일치 여부를 본다. NCP가 자기 region을 kr-standard로 정해뒀으니 SDK도 같은 문자열을 써야 검증을 통과한다.
이걸 알고 나면, region을 잘못 박았을 때 무슨 일이 일어나는지도 예측 가능해진다.
.region(Region.US_EAST_1)— 요청 URL은 endpointOverride 덕에 여전히 NCP로 가지만, 서명은 “us-east-1”로 계산된다. NCP는 자기 region “kr-standard”로 다시 계산하니 두 서명이 다름 → 403 SignatureDoesNotMatch. “키가 잘못됐나?” 하고 키부터 의심하게 되는 함정.- region 자체를 빼면 AWS SDK가 빌드 단계에서 거부한다 (
SdkClientException: Unable to load region).
| 설정 | 결정하는 것 |
|---|---|
endpointOverride | 어디로 갈지 (DNS/TCP) |
pathStyleAccessEnabled | URL을 어떻게 조립할지 (host/{bucket} vs {bucket}.host) |
region | 서명에 들어가는 라벨 |
AWS S3에서는 region 하나가 endpoint와 서명 두 역할을 다 한다. endpoint를 override 한 순간 그 둘이 분리되고, 그제서야 region이 “오직 서명을 위한 라벨”이 된다는 사실이 드러난다. 이걸 의식하지 못한 채 둘 다 박아두면 코드는 동작하지만, 왜 동작하는지를 설명할 수 없는 상태가 된다.
3.2 Presigned URL은 네트워크 호출이 아니다
이건 내가 가장 늦게 깨달은 부분이고, 가장 부끄러운 부분이다.
s3Presigner.presignPutObject(...). 나는 이 메서드가 NCP에 가서 URL을 받아오는 호출이라고 어렴풋이 생각하고 있었다. 그래서 “presigned URL 발급이 느릴 수도 있겠다”는 의심을 트러블슈팅 가설에 넣었다.
아니다. Presign은 100% 로컬 연산이다.
서명 알고리즘 자체가 그렇게 설계되어 있다. SigV4는
- 메서드 (
PUT) - 호스트 (
kr.object.ncloudstorage.com) - 경로 (
/{bucket}/{key}) - 쿼리스트링 (
X-Amz-Date,X-Amz-Expires,X-Amz-SignedHeaders, …) - 정규화된 헤더
- payload hash (presigned URL의 경우는
UNSIGNED-PAYLOAD)
이 모두를 모아서 정해진 방식으로 정규화 → SHA256 → HMAC 체인을 돌려 서명 문자열을 만든다. 이 계산은 클라(이 경우 서버) 머신 안에서 끝나고, 거기에 SecretKey가 곱해진다. NCP에 가서 받아오는 게 아니라, 내가 들고 있는 SecretKey로 내가 만드는 것이다.
이게 왜 중요한가 하면, “presigned URL 발급 자체는 거의 0초”가 단정 가능한 사실이 되기 때문이다. presigned-upload API가 느렸다면 그건 presign 연산이 아니라 그 앞뒤의 다른 무언가(JSON 직렬화, validation, 응답 직렬화, 톰캣 큐잉, 네트워크) 때문이다. 이걸 알고 있었다면 그 자리에서 “1단계는 의심에서 빼도 된다”가 바로 나왔어야 했다.
부수적인 함의 두 가지.
- SecretKey가 곧 서명 권한이다. presign이 로컬 연산이라는 건 SecretKey만 있으면 누구나 URL을 만들 수 있다는 뜻이다. 키 관리가 곧 보안이다.
- presigned URL 발급 자체는 NCP에 어떤 흔적도 남기지 않는다. 객체가 실제로 올라오기 전까지 NCP는 그 URL이 발급된 사실조차 모른다. 그래서 “발급은 됐는데 아무도 안 올렸다”가 그냥 일어난다 — 이게 곧 고아 객체 문제의 출발점이다.
3.3 검증 단계의 range: bytes=0-0 트릭
이건 작은 디테일인데, 의외로 알게 되니 명료해진 부분이라 적어둔다.
목적은 단순하다. 객체가 정말로 올라왔는지 확인하고, 메타데이터(Content-Type, Content-Length)를 가져오고 싶다. 본문 데이터 자체는 필요 없다.
정석은 HeadObject. 본문 없이 메타데이터만 받는다.
내가 쓴 건 GetObject + Range: bytes=0-0. 본문 1바이트만 받는다. 이때 응답이 흥미로운데:
- HTTP 상태는
206 Partial Content Content-Length: 1— 이번 응답이 돌려준 바이트Content-Range: bytes 0-0/12345— 객체 전체는 12345바이트
코드에서 response.contentLength()만 신뢰하면 안 되고 Content-Range의 / 뒤를 파싱해야 객체 전체 크기를 얻는다. 코드에 그렇게 짜여 있긴 한데, HEAD를 쓰면 이 파싱 자체가 필요 없다. 다음에는 HEAD로 가는 게 맞다.
3.4 운영이라면 더 챙겨야 할 것들
해커톤에서는 의식적으로 자른 것들이 많다. 정식 서비스라면 다음을 더 봤어야 한다.
(1) Content-Type을 서명에 묶을지 정책으로 결정
지금은 PUT 할 때 클라이언트가 보낸 Content-Type을 그대로 받는다. 클라가 거짓말을 하면 NCP에는 거짓 헤더로 저장된다. complete 단계에서 잡아내긴 하지만, 신뢰 경계를 더 앞당기고 싶다면 presign 시점에 .contentType(...)을 묶어 클라가 정확히 그 헤더로 PUT 하지 않으면 PUT 자체가 실패하게 할 수 있다. 클라 구현 복잡도와 트레이드오프.
(2) presigned URL 만료시간 단축 10분은 너무 길다. PUT 한 번에 60초도 차고 넘친다. 만료를 짧게 잡고, 만료되면 클라가 재발급 받도록 가이드. URL 유효기간이 짧으면 유출 시 위험도가 그만큼 줄어든다.
(3) 멱등성/재시도 지금 [3단계] complete를 클라가 두 번 호출하면 두 번째 호출에서 무슨 일이 일어날지가 깔끔하지 않다. ACL을 두 번 박는 건 큰 문제는 아니지만, 검증 실패 후 다시 보낸다든가 하는 시나리오가 깔끔하지 않다. complete를 멱등으로 보장하면 클라가 재시도하기 편하다.
(4) 진짜 컨텐츠 검증
Content-Type 헤더는 거짓말할 수 있다. 진짜 이미지인지 보려면 첫 몇 바이트의 magic number를 봐야 한다. JPEG는 FF D8 FF, PNG는 89 50 4E 47, HEIC는 ftyp 박스 안의 heic/heix/mif1 등. 1바이트가 아니라 처음 12바이트 정도를 받아서 체크하는 게 안전하다. 더 가면 ImageIO로 디코딩까지 시도.
(5) CORS 브라우저 클라이언트라면 NCP 버킷에 CORS 설정을 박아야 PUT이 통과한다. 이번엔 iOS 네이티브라 안 필요했지만 웹/리액트 네이티브로 확장하는 순간 첫 번째로 깨지는 부분.
(6) CDN과 캐시 검증이 끝난 객체를 public으로 열고 공개 URL을 그대로 저장하는 지금 모델은 CDN과 궁합이 가장 좋다. URL이 영구적이고 안정적이라 캐시 키로도 그대로 쓸 수 있다. NCP의 CDN+ 같은 걸 앞에 두고 이미지 조회 트래픽을 캐시하면 NCP Object Storage가 받을 부담이 한참 줄어든다.
(7) 메트릭과 모니터링 지금 코드에서는 “presign 발급에 몇 ms 걸렸는가”, “complete의 GetObject가 몇 ms 걸렸는가”가 로그에 안 잡힌다. Micrometer로 단계별 타이머를 박았다면 4장의 트러블슈팅이 추측이 아니라 데이터로 끝났을 것이다.
(8) 고아 객체 정리 배치 presigned URL 발급 후 PUT만 하고 카드를 만들지 않은 객체, 혹은 PUT 후 complete 전에 끊긴 객체. 객체 키에 만료 메타데이터를 박고, 일정 시간 이상 카드에 연결되지 않은 객체를 청소하는 배치가 필요하다.
(9) 객체 키 저장 vs 공개 URL 저장
지금은 카드 DB에 공개 URL을 통째로 저장한다. 구현은 단순하지만 스토리지 엔드포인트/버킷이 바뀌는 순간 DB 마이그레이션이 필요해진다. 정식 서비스라면 URL이 아니라 objectKey만 저장하고, 응답을 만들 때 동적으로 URL을 조립하는 게 인프라 변경에 강하다.
---
4. 요청 지연의 진짜 원인은 뭐였을까
이제 마지막 발표 직전에 터졌던 요청 지연을 다시 본다. 그때는 “와이파이가 안 좋아서”로 닫았지만 클라 코드를 읽고 나니 그 외에도 개선 방향이 보였다
4.1 단계를 다시 쪼개기
발생할 수 있는 지점은 정확히 네 군데다.
| # | 단계 | 무슨 일 | 서버 흔적 |
|---|---|---|---|
| 1 | POST /v1/images/presigned-upload | 서버가 SigV4 로컬 서명 → URL 반환 | 있음 |
| 2 | PUT {presignedUrl} | 클라 → NCP 직통 업로드 | 없음 |
| 3 | POST /v1/images/complete | 서버가 NCP에 GetObject + ACL PUT | 있음 |
| 4 | POST /v1/mistakes | 서버가 DB에 카드 저장 | 있음 |
3.2에서 봤듯이 1단계는 본질적으로 빠르다. presign은 로컬 연산이고, 응답 페이로드도 작다. 어떤 식으로든 시간이 오래 걸릴 구조가 아니기에 1단계는 후보에서 뺀다.
4단계는 작은 INSERT 한 번이라 몇분씩 레이턴시가 나올 수 없다.
3단계는 서버가 NCP에 두 번 HTTP 요청을 보낸다(GetObject + putObjectAcl). 둘 다 작은 요청이라 평상시 합쳐서 100~500ms 수준이다. NCP가 통째로 느렸다면 모를까 가능성이 낮다. 일단 보류.
남는 건 2단계(클라 → NCP PUT).
4.2 클라 코드에서 발견한 힌트
클라 코드에서 사진을 인코딩하는 부분이 이렇다.
// WriteMistakeViewController.swift
guard let image = selectedImage,
let imageData = image.pngData() else {
print("⚠️ 이미지를 데이터로 변환하는 데 실패했습니다.")
return
}
let filename = "ios_upload_\(Int(Date().timeIntervalSince1970)).png"
let contentType = "image/png"
let contentLength = imageData.countimage.pngData(). PHPicker에서 고른 사진을 PNG로 인코딩하고 있다.
PNG는 무손실 포맷이다. 스크린샷이나 도식에는 적합하지만 사진에는 안 어울리는 포맷이다. iPhone 카메라 사진은 보통 12MP(4032×3024)이고, 이걸 PNG로 떨구면 20~40MB가 나온다. 같은 사진을 image.jpegData(compressionQuality: 0.7)로 떨구고 1080px로 리사이즈하면 200~500KB다. 보통 40~80배 차이.
서버의 max-file-size는 처음엔 10MB였다. 그런데 구현 중 PNG가 10MB를 넘어 1단계 issuePresignedURL에서 400으로 잘리는 일이 반복됐다. 그때 제시해줬어야 하는 건 클라 측에서 사진을 압축/리사이즈하는 것이었다. 그런데 우리는 서버 상한을 30MB로 올리는 방향을 선택했다. 그 시점에 이미 책임의 위치를 잘못 잡은 셈이다.
요청 지연이 발생한 건 와이파이 상태가 안좋아졌을 때였다. 30MB 안에 들어가는 PNG라면 12MP 카메라 사진을 그대로 PNG로 떨군 2030MB짜리 클라이언트가 1단계 검증을 통과해서 PUT을 시작한다. 그리고 그 2030MB가 해커톤 현장 와이파이를 통과해야 한다.
- 일반적인 행사장 공용 와이파이 업로드 대역폭: 1
3Mbps (실효 125375KB/s) - 25MB를 125KB/s로 올리면: 약 200초 (≈ 3분 20초)
- 거기에 TLS handshake, NCP 측 큐잉, 패킷 손실 재전송 같은 게 끼면 대충 3분정도가 나올 수 있을 것 같다.
만약 사진을 JPEG 0.7 + 1080px로 줄여서 300KB였다면 같은 와이파이에서 2~3초로 성공했을 것이다.
즉 결론은 이렇다.
요청 지연의 결정적 원인은 와이파이가 아니라 페이로드였다. 와이파이는 그 페이로드를 처리할 수 없을 만큼 좁았을 뿐이고 페이로드를 60배정도 줄일 여지가 있었다.
4.3 그 외에 그 자리에서 같이 봤어야 할 것들
사고 이후 클라 코드를 다시 읽어보니 그 자리에서 같이 살펴봤다면 훨씬 빨리 단계를 좁힐 수 있었을 단서들이 몇 가지 보였다. 핵심은 “클라가 이렇게 잘못했다”가 아니라 서버 쪽에서 “이게 페이로드 문제일 수 있다”는 가능성을 그 자리에서 떠올렸어야 했고 그러지 못해서 max-file-size를 올리는 우회로 가버렸다는 점이다.
(1) 단계별 로그가 이미 찍히고 있었다
🚀 [1단계 시작] Presigned URL 발급 요청 중...
🚀 [2단계 시작] 발급 성공 -> 바이너리 업로드 중...
🚀 [3단계 시작] 바이너리 업로드 성공 -> 서버 최종 완료 검증 요청 중...
🚀 [최종 단계 시작] 검증 성공 -> 최종 실수 카드 생성 중...클라가 이미 단계별로 로그를 찍어두고 있었다. 그 자리에서 클라 콘솔을 같이 봤다면 “[2단계 시작]은 찍혔는데 [3단계 시작]이 안 찍힌다”가 바로 보였을 것이고 그러면 PUT 구간이라는 단정이 즉시 가능했다. 그런데 그 단서를 보러 갈 생각조차 못 하고 “와이파이 같다”로 닫았다. 단서가 부족했던 게 아니라 서버 쪽에서 “PUT 구간은 서버 로그에 안 잡히니까 클라 로그를 봐야 한다”는 사실을 의식하지 못한 것이 1차 원인이다.
(2) 진단에 쓸 단서들이 클라에 없었던 것 — 서버가 같이 부탁했어야 할 부분
지금 코드를 보면 클라 측에 업로드 progress 콜백, 명시적 timeout, 메인 스레드를 벗어난 이미지 인코딩 같은 것들이 빠져 있다. 사고 당시 셋 중 하나라도 있었다면 progress가 한 자리에 멈춰 있는지, timeout이 떨어졌는지, UI가 함께 멈췄는지 원인을 훨씬 빨리 좁힐 수 있었다.
다만 이걸 “클라가 빠뜨렸다”로 정리하면 책임 전가를 하면 안된다. 서버 쪽에서 “PUT 단계가 우리 로그에 절대 안 잡힌다”는 한계를 의식하고 있었다면 클라 구현 가이드에 progress / timeout / 비동기 인코딩이 “진단 단서”로 같이 들어갔을 것이다. 그 가이드가 없었던 채로 사고가 났고 사고가 났을 때 같이 들여다볼 도구가 없어서 capacity을 올리는 우회로 빠졌다.
요약하면 4.3의 항목들은 클라의 결함 목록이 아니라 이 아키텍처에서 서버가 의식적으로 채워줬어야 할 진단 인터페이스의 부재 목록이다.
4.4 그럼 서버 쪽 책임은 없었나
있다.
(1) 서버가 받아들이는 페이로드 상한이 사실상의 정책 그리고 그 상한을 올린 순간이 사고의 출발점
4.2에서 적은 그대로다. 처음 max-file-size: 10MB였을 때 PNG가 자꾸 거부되니까 우리는 30MB로 올렸다. 이 결정 한 줄이 사실은 가장 큰 책임이다. 10MB에서 거부가 일어났을 때 그 자리에서 던졌어야 할 질문은 **“왜 사진 하나가 10MB를 넘느냐”**였다. 즉 클라 측 압축 부재. 그런데 우리는 그걸 묻지 않고 서버 상한을 풀어버렸다. 증상을 막은 게 아니라 증상에 맞춰 정책을 풀어버린 셈이고 그게 요청 지연 사고를 직접 가능하게 했다.
같은 위치에 “단, 가급적 1MB 이하로 압축해서 보내주세요”라는 가이드가 같이 갔어야 했다. API 응답 메시지든 가이드 문서든 서버 정책과 클라 압축 정책을 같은 자리에 두지 않은 것이 책임의 한 축이다.
(2) 단계별 지연을 측정할 도구를 안 박았다 만약 presign 발급 ms, complete의 GetObject ms, putObjectAcl ms를 각각 메트릭으로 박았다면 “1, 3, 4단계는 평소와 같다”가 데이터로 즉시 확인 가능했을 거고 그 자리에서 2단계로 단정할 수 있었다. 지금 구조에서는 추측만 가능하다.
4.5 다시 추적한 결론
| 후보 | 판정 | 근거 |
|---|---|---|
| 1단계 (presigned 발급) | 무죄 | presign은 로컬 SigV4 연산. 본질적으로 빠르다 |
| 2단계 (PUT) | 유죄 | PNG 무압축 페이로드(20~30MB) × 좁은 와이파이 |
| 3단계 (complete) | 무죄 가능성 높음 | NCP에 작은 요청 두 번. 평소 수백 ms로 |
| 4단계 (mistakes 저장) | 무죄 | 작은 INSERT |
진짜 원인은 와이파이가 아니라 클라이언트의 pngData(). 와이파이는 그 페이로드를 감당할 수 없었을 뿐이다.
다음에 같은 상황을 만나면 그 자리에서 봐야 할 것
- 클라 단계별 로그를 보고 어느 사이에서 멈춰 있는지 본다 (위치 좁히기)
- 페이로드 크기를 본다 (
contentLength) - 위 둘이 PUT 구간 + 큰 페이로드라면 → 클라 측 압축/리사이즈 즉시 조정
- 그게 아니라면 서버 메트릭과 NCP 상태로 넘어간다
이 4단계를 그 자리에서 못 돌렸던 게 와이파이 때문이 아니라 흐름 전체에 대한 내 이해의 얕음 때문이었다는 것이 이 회고의 결론이다.
---
5. 결론
이번에 구현한 흐름은 동작했다. 결정에는 그 자리의 이유가 있었고 그때의 제약 안에서는 합리적인 선택이었다고 생각한다.
그럼에도 부끄러웠던 건 단 한 가지였다. 내가 짠 코드인데 그 코드가 왜 동작하는지를 즉시 설명할 수 없었다. 그게 가장 노골적으로 드러난 게 업로드 지연 장애였고 그 자리에서 “와이파이 같다”로 닫고 넘어간 게 실질적으로 팀원에게 피해로 이어졌다.
다음에는 같은 실수를 반복하면 안된다.
(1) 최소한 내 코드의 주인은 내 것이어야 한다. 해커톤이기에 시간이 없어서 어쩔 수 없었다는 말은 변명이 될 수 없다. 내가 구현한 코드의 흐름을 미리 이해하고 있었다면 이번 이슈의 추적이 훨씬 빨랐다. AI를 활용한 개발은 코드를 내 것으로 만들어주지는 않는다. 한 번은 안을 파봐야 코드 주인이 된다.
(2) “되니까 됐다”로 닫지 않는다. 이번에 동작한 코드들 중 몇 개는 “왜 동작하는지”가 아니라 “동작한다”라는 것만 확인된 채로 남아있었다. Content-Type을 안 묶은 결정, GetObject + range(0-0) 트릭, presigner를 별도 빈으로 만든 것. 각각의 이유가 명확히 머릿속에 있어야 했다. 동작이 곧 정합성은 아니다.
(3) 장애 앞에서 외부 변수로 도망가지 않는다. “와이파이 탓”은 외부 변수다. 외부 변수로 결론을 내면 그 자리에서 사고가 멈춘다. 같은 와이파이에서 페이로드만 60배 줄였으면 됐던 문제였다. 장애를 단계별 타임스탬프로 분해해서 안쪽에서부터 좁혀가는 습관. 클라 로그, 서버 로그, 외부 의존성, 그 순서로. 닫는 결론을 내리기 전에 한 번씩은 “내가 더 좁힐 수 있는가”를 물어봐야 한다.
이 글을 쓰는 지금은 발표 다음 날이다. 그때 그 자리에서 못 짚었던 것을 지금 시간을 들여 짚어보는 것 자체가 부끄럽기도 하고 한편으로는 다음 프로젝트로 가져갈 자산이 하나 늘었다는 뜻이기도 하다. 결과가 좋았으니 괜찮다고 할 수 있지만 이번엔 운이 좋았지만 다음엔 아닐 수 있다.
다음 같은 자리에서는, 자리에서 즉시 짚을 수 있는 사람이 되고 싶다.

