Spring Boot 프로젝트를 운영하다 보면 500 에러가 터진다. 로그 보고, 원인 파악하고, 코드 고치고, PR 올리고. 매번 같은 루틴이다.
“에러 나면 AI가 코드 보고 알아서 고쳐서 PR까지 올려주면 안 되나?”
이 생각에서 시작했다. 사람이 해야 할 건 PR 리뷰뿐인 봇을 만들어보자.
---
전체 흐름
Spring Boot 500 에러
→ POST /webhook/error
→ Discord 에러 알림
→ 스택트레이스 파싱 → 소스코드 조회 (GitHub API 또는 로컬 파일) → import 기반 관련 파일 추가 조회
→ AI 분석/수정 → 응답 검증
→ GitHub PR 생성
→ Discord 완료 알림봇은 Python + FastAPI로 만들었고, 이 파이프라인 전체가 하나의 비동기 태스크로 실행된다. 각 단계를 순서대로 풀어보겠다.
---
1. 에러 수집 — Spring Boot에서 봇으로
문제
Spring Boot 앱에서 500 에러가 발생했을 때, 별도의 모니터링 시스템 없이 봇 서버로 에러 정보를 바로 전달해야 했다.
선택: @RestControllerAdvice + WebClient
Spring의 @RestControllerAdvice로 모든 미처리 예외를 캐치하고, WebClient로 봇에 비동기 전송한다.
@ExceptionHandler(Exception.class)
public ResponseEntity<Object> handleException(Exception ex, HttpServletRequest request) {
sendErrorReport(ex, request); // 비동기 전송
return ResponseEntity.status(500).body(Map.of("error", "Internal Server Error"));
}전송은 subscribe()로 논블로킹 처리한다. 봇 서버가 죽어있어도 Spring Boot의 응답 시간에 영향이 없다. 전송 실패는 warn 로그만 남기고 넘어간다 — 에러 리포팅이 본 서비스 장애로 이어지면 안 되기 때문이다.
전송 데이터
{
"errorType": "java.lang.NullPointerException",
"errorMessage": "Cannot invoke method on null reference",
"stackTrace": "java.lang.NullPointerException: ...\\\\\\\\n\\\\\\\\tat com.myapp.service.UserService.getUser(UserService.java:45)\\\\\\\\n\\\\\\\\t...",
"requestUrl": "GET /api/users/123",
"timestamp": "2026-02-16T10:30:00Z"
}Spring Boot 프로젝트에 ErrorReportFilter.java와 ErrorReportDto.java 두 파일만 복사하면 연동 끝이다.
---
2. 에러 수신 — FastAPI Webhook
왜 FastAPI인가
봇 서버의 핵심 요구사항은 두 가지였다:
- 외부 API 호출(GitHub, OpenAI, Discord)이 많으므로 비동기 처리 필수
- Webhook 수신 후 즉시 응답하고, 분석은 백그라운드에서 실행
FastAPI는 async/await을 네이티브로 지원하고, Pydantic으로 요청 검증이 자동으로 이루어진다.
@app.post("/webhook/error")
async def receive_error(report: ErrorReport):
task = asyncio.create_task(process_error(report))
task.add_done_callback(_log_task_exception)
return {"status": "received"}Webhook은 즉시 {“status”: “received”}를 반환하고, 실제 파이프라인은 create_task로 백그라운드 실행한다. Spring Boot 쪽에서 봇의 처리 완료를 기다릴 이유가 없기 때문이다.
중복 에러 필터링
같은 에러가 연속으로 들어오면 무시한다. 에러 타입 + 메시지 + 스택트레이스 앞 200자를 SHA-256으로 해싱해서 30분간 같은 해시가 들어오면 건너뛴다.
DEDUP_TTL = 1800 # 30분
def _is_duplicate(report):
key = hashlib.sha256(
f"{report.errorType}{report.errorMessage}{report.stackTrace[:200]}".encode()
).hexdigest()
if key in _recent_errors:
return True
_recent_errors[key] = time.time()
return False---
3. 스택트레이스 파싱 — 어떤 파일을 봐야 하는가
문제
Java 스택트레이스에는 Spring 내부 코드, 라이브러리 코드가 섞여 있다. AI에게 전체를 던지면 노이즈가 너무 많다. 내 프로젝트 코드만 골라내야 한다.
선택: 정규식 + base_package 필터
pattern = rf"at ({re.escape(base_package)}[\\\\\\\\w.]+)\\\\\\\\.(\\\\\\\\w+)\\\\\\\\((\\\\\\\\w+\\\\\\\\.java):(\\\\\\\\d+)\\\\\\\\)"base_package(예: com.myapp)로 시작하는 라인만 매칭한다. com.myapp.service.UserService.getUser(UserService.java:45)에서:
- 클래스: com.myapp.service.UserService
- 메서드: getUser
- 라인: 45
클래스 경로는 파일 경로로 변환한다: com.myapp.service.UserService → src/main/java/com/myapp/service/UserService.java
이렇게 하면 org.springframework이나 java.lang 같은 외부 코드는 자동으로 걸러진다.
---
4. 소스코드 조회 — GitHub API와 로컬 파일
두 가지 조회 방식
소스코드 조회는 환경변수 SOURCE_MODE로 두 가지 모드를 선택할 수 있다:
- github (기본값): GitHub API로 원격 조회. 봇과 Spring Boot 앱이 같은 서버에 있을 필요 없고, 브랜치 지정 조회 가능
- local: 로컬 파일시스템에서 직접 읽기. API 호출 비용 없이 빠르고, import depth를 깊게 탐색할 수 있음
def fetch_file_content(file_path: str) -> str | None:
if settings.source_mode == "local":
try:
return (Path(settings.local_source_path) / file_path).read_text(encoding="utf-8")
except Exception:
return None
try:
content = _get_repo().get_contents(file_path, ref=settings.github_base_branch)
return content.decoded_content.decode("utf-8")
except Exception:
return None분기 지점은 fetch_file_content() 하나뿐이다. 이 함수를 반복 호출하는 fetch_files()나 PR 생성 로직은 변경 없이 그대로 동작한다. 대시보드에서도 GitHub/Local 모드를 런타임에 전환할 수 있다.
로컬 모드는 Docker 볼륨 마운트로 소스코드를 컨테이너에 연결한다:
volumes:
- .:/workspace/source:roPyGithub + run_in_executor
PyGithub는 동기 라이브러리다. FastAPI의 비동기 흐름을 깨지 않으려면 run_in_executor로 감싸야 한다.
loop = asyncio.get_running_loop()
files = await loop.run_in_executor(None, partial(fetch_files, file_paths))비동기 GitHub 클라이언트(gidgethub 등)도 고려했지만, PyGithub의 API가 더 직관적이고 PR 생성까지 한 라이브러리로 처리할 수 있어서 선택했다. executor로 감싸는 보일러플레이트는 감수할 만했다.
Import N-depth 탐색
에러가 UserService.java에서 터졌다고 해서 그 파일만 보면 안 된다. UserService가 import하는 UserRepository, UserDto 등도 AI에게 줘야 맥락을 파악할 수 있다.
error_files = dict(files) # 스택트레이스에 직접 등장한 파일
all_files = dict(files)
for _ in range(settings.import_depth):
new_paths = []
for source_code in all_files.values():
new_paths.extend(
extract_related_imports(source_code, base_package, set(all_files.keys()))
)
if not new_paths:
break
new_files = await loop.run_in_executor(None, partial(fetch_files, new_paths))
all_files.update(new_files)
context_files = {k: v for k, v in all_files.items() if k not in error_files}import문에서 base_package로 시작하는 것만 추출하므로 외부 라이브러리는 빠진다. IMPORT_DEPTH=2로 설정하면 2단계까지 연쇄적으로 따라간다.
핵심은 에러 파일과 참고 파일을 분리하는 것이다. 이 구분은 AI 프롬프트에서 중요하게 쓰인다.
---
5. AI 분석 — 프롬프트 설계와 신뢰성 확보
왜 GPT-4o-mini인가
처음에는 Claude API를 사용했다가 OpenAI로 변경했다. 이유:
- gpt-4o-mini가 비용 대비 코드 수정 품질이 괜찮았다
- JSON 형식 응답의 안정성이 좋았다 (파싱 실패율이 낮음)
- 이 봇은 단순 에러(NPE, 타입 에러 등)를 타겟하므로 최상위 모델이 필요하지 않았다
AI Provider 추상화
나중에 모델을 바꿀 수 있도록 Protocol 패턴을 적용했다.
class AIProvider(Protocol):
def call(self, system_prompt: str, user_prompt: str) -> str: ...
_PROVIDERS: dict[str, type] = {
"openai": OpenAIProvider,
}환경변수 AI_PROVIDER=openai로 선택하고, 새 모델을 추가하려면 AIProvider를 구현하는 클래스를 하나 만들어 _PROVIDERS에 등록하면 된다. ai_service.py는 수정할 필요 없다.
프롬프트 구조
AI에게 보내는 프롬프트의 핵심은 에러 파일과 참고 파일을 명확히 분리하는 것이다.
## 에러 발생 소스 코드 (스택트레이스에 포함된 파일)
### src/main/java/com/myapp/service/UserService.java
(코드)
## 관련 참고 코드 (import된 프로젝트 내부 파일)
### src/main/java/com/myapp/repository/UserRepository.java
(코드)이렇게 분리하면 AI가 “이 파일이 에러 발생 지점이고, 이건 맥락 파악용”이라는 구분을 갖게 된다. 분리하지 않으면 참고 파일까지 불필요하게 수정하는 경우가 있었다.
응답은 구조화된 JSON으로 강제한다:
{
"analysis": "에러 원인 상세 분석",
"root_cause": "근본 원인 한 줄 요약",
"fix_description": "수정 내용 상세 설명",
"files": [{"path": "파일 경로", "content": "수정된 전체 코드"}],
"summary": "PR 제목용 한 줄 요약"
}파싱 실패 시 피드백 재시도
AI가 JSON이 아닌 응답을 주면, 피드백을 붙여 1회 재시도한다.
# 1차 시도
try:
text = provider.call(SYSTEM_PROMPT, user_prompt)
return json.loads(text)
except json.JSONDecodeError:
pass
# 2차 시도: 피드백 포함
retry_prompt = user_prompt + "\\\\\\\\n\\\\\\\\n## 주의\\\\\\\\n이전 응답이 유효한 JSON이 아니었다. 반드시 JSON 형식으로만 응답하라."
text = provider.call(SYSTEM_PROMPT, retry_prompt)
return json.loads(text)무한 재시도는 하지 않는다. 2번 실패하면 포기하고 Discord로 실패 알림을 보낸다.
AI 응답 검증
AI를 신뢰하되 검증한다. PR 생성 전에 두 가지를 확인한다:
def _validate_ai_result(result, known_files):
for f in result["files"]:
if f["path"] not in known_files: # 실제 조회한 파일에 없는 경로?
return f"알 수 없는 파일 경로: {f['path']}"
if not f["content"].strip(): # 빈 내용?
return f"빈 파일 내용: {f['path']}"검증 실패 시 PR 생성을 중단하고 Discord로 실패 사유를 알린다. 잘못된 코드가 PR로 올라가는 것보다 실패를 알려주는 게 낫다.
---
6. PR 생성 — GitHub API로 브랜치부터 PR까지
플로우
# 1. base 브랜치의 최신 SHA
base_ref = repo.get_git_ref(f"heads/{base_branch}")
base_sha = base_ref.object.sha
# 2. 새 브랜치 생성
repo.create_git_ref(f"refs/heads/{branch_name}", base_sha)
# 3. 수정된 파일 커밋
for f in files:
existing = repo.get_contents(f["path"], ref=branch_name)
repo.update_file(path=f["path"], message=f"fix: {summary}",
content=f["content"], sha=existing.sha, branch=branch_name)
# 4. PR 생성
pr = repo.create_pull(title=f"fix: {summary}", body=pr_body,
head=branch_name, base=base_branch)브랜치명은 fix/error-{error_id}-{timestamp} 형식으로 자동 생성한다.
PR 본문
PR 본문에는 리뷰어가 판단하기 위한 정보를 모두 담는다:
- 에러 정보 테이블 (타입, 메시지, 요청 URL, 발생 시간)
- 근본 원인
- AI 분석
- 수정 내용 설명
- 수정된 파일 목록
- unified diff (원본 vs 수정 코드)
특히 diff는 difflib.unified_diff로 생성한다. 리뷰어가 AI가 뭘 바꿨는지 PR 본문만 보고 바로 파악할 수 있다.
---
7. 알림 — Discord Webhook
왜 Discord인가
Slack도 고려했지만 Discord를 선택한 이유:
- Webhook 설정이 간단 (URL 하나면 끝)
- Embed 메시지로 구조화된 알림 가능
- 별도 앱 등록이나 OAuth 없이 바로 사용 가능
알림 종류
세 가지 알림을 보낸다:
- 에러 발생 (빨간색) — 에러 타입, 요청 URL, 메시지, 발생 시간
- PR 생성 완료 (초록색) — 변경 사항 요약, PR 링크
- 처리 실패 (주황색) — 에러 정보 + 실패 사유
모든 알림에 tenacity로 2회 재시도를 건다. Discord Webhook이 일시적으로 실패해도 알림을 놓치지 않기 위해서다.
@retry(stop=stop_after_attempt(2), wait=wait_fixed(1), reraise=True)
async def send_error_alert(report) -> None:
embed = {
"title": "🚨 500 에러 발생",
"color": 0xFF0000,
"fields": [
{"name": "에러 타입", "value": report.errorType, "inline": True},
{"name": "요청", "value": report.requestUrl, "inline": True},
{"name": "메시지", "value": report.errorMessage[:1024]},
],
}
await _post_webhook({"embeds": [embed]})---
8. 실시간 대시보드 — SSE
왜 WebSocket이 아니라 SSE인가
대시보드의 요구사항은 단순하다:
- 서버 → 클라이언트 단방향 전송 (파이프라인 상태)
- 클라이언트 → 서버는 일반 HTTP 요청으로 충분 (테스트 에러 전송 등)
SSE가 WebSocket보다 나은 점:
- 구현이 단순 (EventSourceResponse + asyncio.Queue)
- 브라우저의 EventSource API가 자동 재연결을 내장
- HTTP/2 환경에서 커넥션 오버헤드가 적음
구현: Pub/Sub 패턴
_subscribers: set[asyncio.Queue] = set()
async def emit(event: PipelineEvent) -> None:
payload = asdict(event)
for q in _subscribers:
q.put_nowait(payload)
async def subscribe() -> AsyncGenerator[dict, None]:
q: asyncio.Queue = asyncio.Queue(maxsize=256)
_subscribers.add(q)
try:
while True:
yield await q.get()
finally:
_subscribers.discard(q)파이프라인의 각 단계에서 emit()을 호출하면, 모든 구독자(대시보드 탭)에게 브로드캐스트된다. 구독자가 느려서 큐가 꽉 차면 해당 구독자를 제거한다.
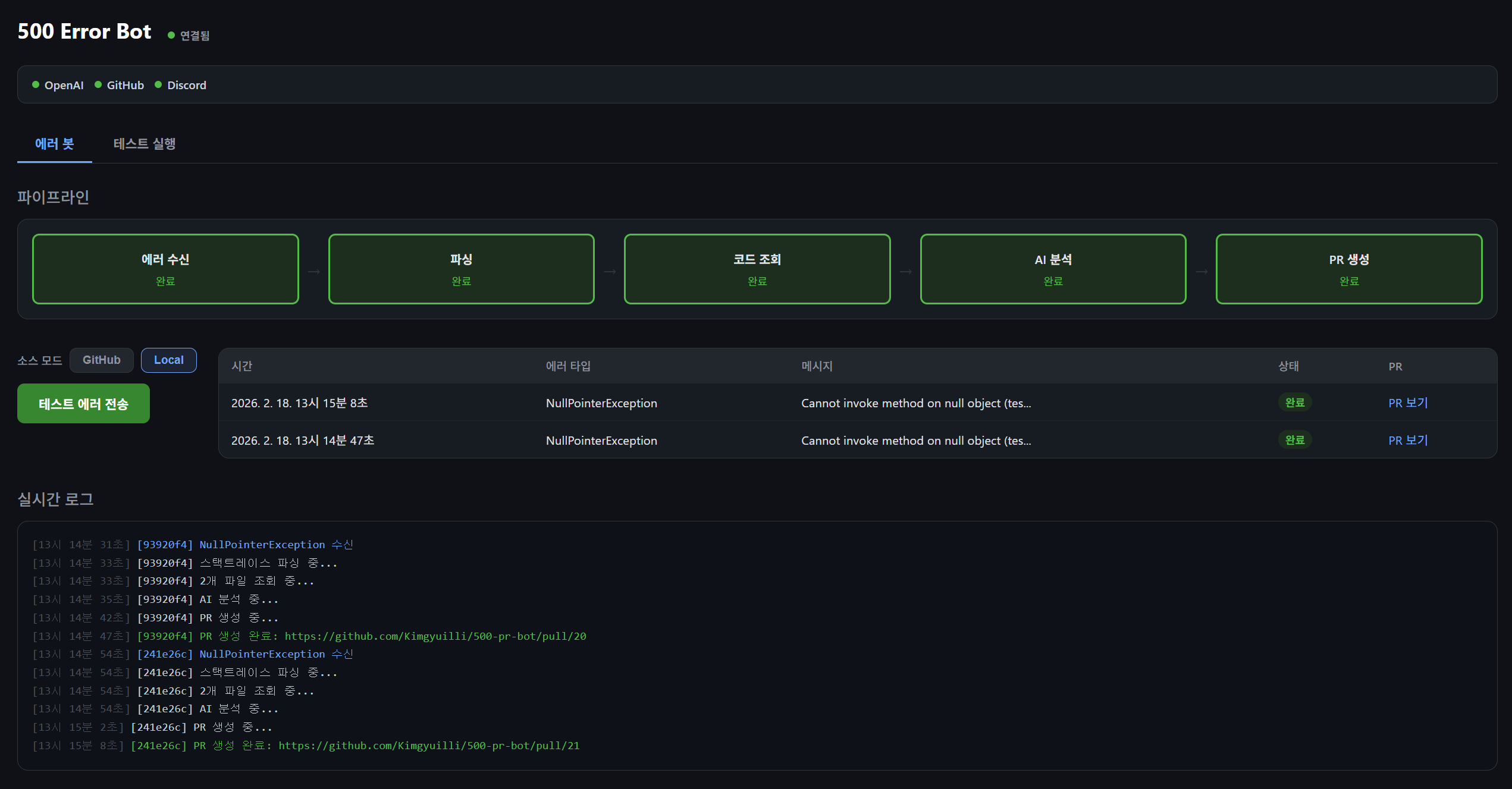
대시보드 기능
- 소스 모드 전환: GitHub/Local 모드를 대시보드에서 바로 전환 가능
- 파이프라인 시각화: 5단계(수신 → 파싱 → 코드 조회 → AI 분석 → PR 생성) 상태 표시
- 에러 히스토리: 최근 50건 테이블, 클릭하면 상세 모달 (스택트레이스, AI 분석, PR 링크)
- 실시간 로그: SSE 이벤트를 시간순으로 표시
- 서비스 상태: OpenAI, GitHub, Discord 연결 상태 (60초 주기 헬스체크)
- 테스트 실행: pytest를 대시보드에서 원클릭 실행, 결과 실시간 스트리밍
---
한계와 트레이드오프
AI 코드 수정의 한계:
- 단순 에러(NPE, 타입 에러)에는 잘 작동하지만, 복잡한 비즈니스 로직 에러는 한계가 있다
- AI가 생성한 코드는 반드시 리뷰 후 머지해야 한다 — 자동 머지는 의도적으로 지원하지 않는다
소스코드 조회의 트레이드오프:
- GitHub 모드: 봇을 어디서든 배포할 수 있지만, 배포 후 추가 커밋이 있으면 실제 실행 중인 코드와 다를 수 있다
- 로컬 모드: 실행 중인 코드와 동일한 소스를 보장하고 속도도 빠르지만, 봇과 소스가 같은 서버에 있어야 한다
- 두 모드를 환경변수와 대시보드 UI로 전환할 수 있으므로, 상황에 맞게 선택하면 된다
확장성:
- 현재 Spring Boot(Java)에 특화되어 있다. 다른 언어를 지원하려면 stack_trace_parser.py의 정규식만 바꾸면 된다
- AI 모델 교체는 Provider 패턴으로 준비되어 있다
---
마치며
“500 에러 → AI 자동 수정 → PR” 파이프라인을 만들었다.
완벽한 자동 수정 봇이 아니다. AI가 만든 코드를 무조건 신뢰할 수는 없다. 하지만 “에러 발생 → 원인 분석 → 수정 코드 제안 → PR로 리뷰 요청”까지의 루틴을 자동화하는 것만으로도, 에러 대응에 쓰는 시간을 크게 줄일 수 있을걸로 기대된다.