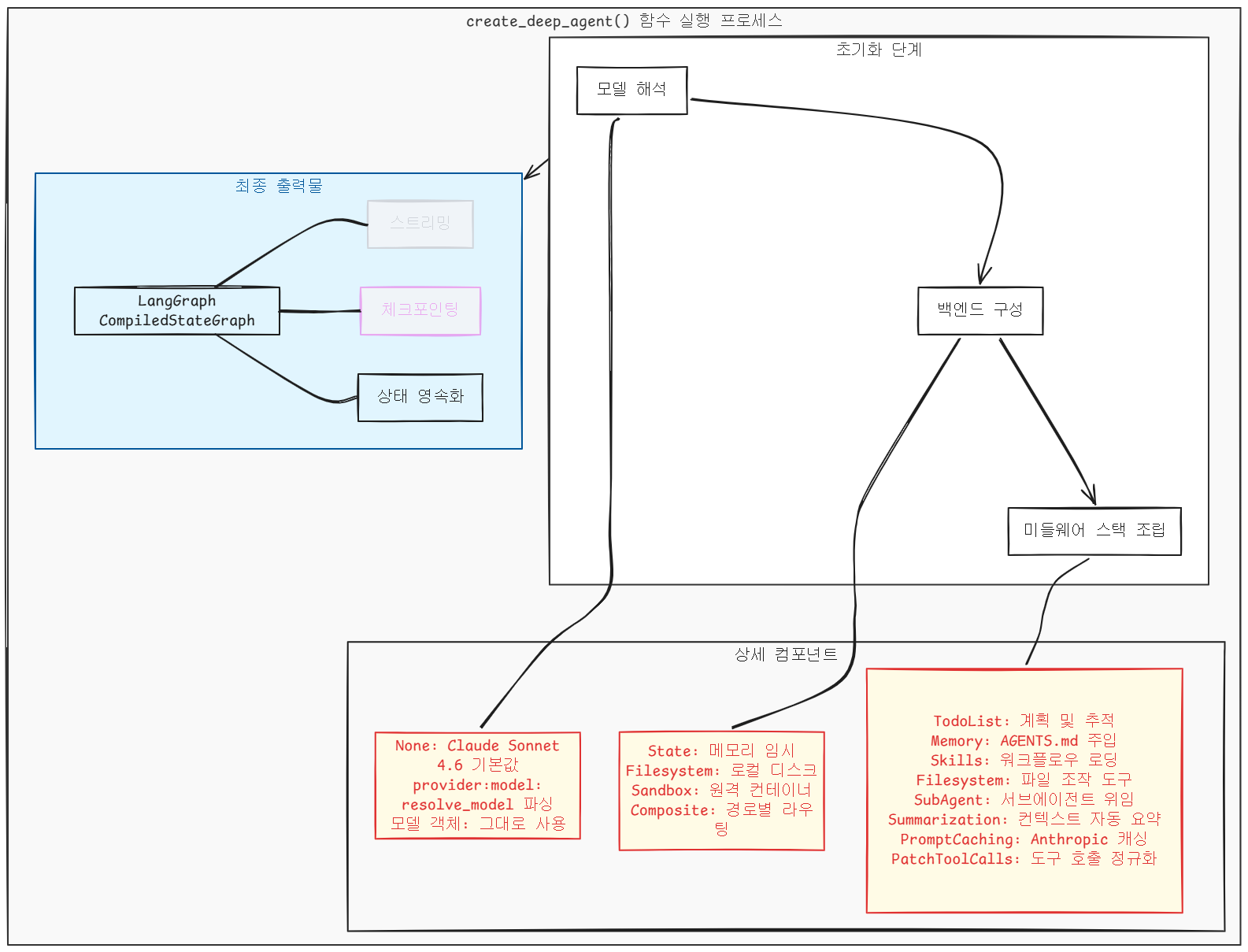
들어가며
최근에 내 개인 LLM Wiki를 구축했다.
처음부터 “LLM Wiki를 만들어야겠다”는 거창한 목표가 있었던 것은 아니다. 나는 계속 기록을 하고 싶었고 그 기록을 다시 꺼내 쓸 수 있는 구조가 필요하다고 느끼고 있었는데 한달 전에 LLM Wiki에 대한 글을 보게 됐고 이번에 시간이 남는 김에 만들어보자고 마음을 먹게 됐다.
개발을 공부하다 보면 좋은 글을 만나고 문제를 해결하다가 시행착오를 겪고 나중에 다시 보면 분명 도움이 될 만한 순간들이 생긴다. 그런데 그 순간들은 생각보다 쉽게 흩어진다. 어떤 글은 브라우저 북마크에 있고 어떤 메모는 노션 어딘가에 있고 어떤 작업 과정은 터미널 히스토리나 AI 대화 안에만 남아 있다. 시간이 지나면 “그때 뭘 보고 해결했더라?”부터 다시 추적하기가 어렵다.
나는 이런 흐름이 계속 아쉬웠다.
나는 개발자를 지향하는 학습자이고 동시에 기록하는 사람이고 싶다. 새롭게 본 것, 배운 것, 실수한 것을 그냥 지나치지 않고 싶다. 내 경험과 실수가 다음 어려움을 해결하는 데 작은 자산이 되었으면 했다. 나중에는 그 기록을 바탕으로 회고글이나 블로그 글도 쓰고 싶었다.
물론 1차 독자는 외부 독자가 아니라 미래의 나다. 내가 왜 그렇게 생각했는지, 어디서 막혔는지, 무엇을 배웠는지를 다시 볼 수 있어야 했다.
그래서 필요했던 것은 단순한 자료 창고가 아니었다.
내가 필요했던 것은, 흩어진 자료와 경험을 모아두고 나중에 다시 쓸 수 있게 해주는 기록 시스템이었다.
LLM Wiki라는 방식
LLM Wiki를 처음 본 것은 Karpathy의 LLM Wiki 아이디어 파일이었다. 다만 해당 글은 작은 아이디어 형태의 글이고 시간이 지나면 사람들이 이 아이디어를 확장해주지 않을까? 생각을 하고 넘어갔다. 그러다 이번에 만들어봐야겠다고 생각하게 된건 그것을 Obsidian, Claude Code, Graphify와 연결해서 설명한 브레인 트리니티의 영상을 통해서였다. 같이 참고한 프롬프트 & 가이드 문서도 있었다.
여기서 가장 와닿았던 점은 RAG와 LLM Wiki를 구분하는 관점이었다.
RAG는 질문할 때마다 관련 문서를 다시 찾고, 그때그때 답을 조립한다. 반면 LLM Wiki는 원본 자료를 미리 읽고 AI가 구조화된 wiki 문서로 컴파일해둔다. 질문할 때마다 새로 찾는 것이 아니라 지식이 조금씩 쌓이는 구조에 가깝다.
이 방식이 내 문제와 잘 맞았다. 나는 검색만 잘하고 싶었던 것이 아니라 내 경험과 자료가 시간이 지나며 쌓이길 원했다. 좋은 글을 봤다는 사실보다 중요한 것은 “내가 왜 그 글에 반응했는가”였다. 작업하다 막혔다는 사실보다 중요한 것은 “왜 막혔고, 어떻게 풀었고, 다음에는 무엇을 다르게 할 수 있는가”였다.
그래서 기본 구조도 카파시가 제시한대로 단순하게 잡았다.
llm-wiki/
├── raw/
├── wiki/
└── Output/raw/는 원본을 보존하는 곳이다. 웹에서 클리핑한 글, 유튜브 내용, 작업 로그, 회고 초안, AI 대화 기록 같은 것들을 가능한 한 원본 그대로 둔다.
wiki/는 AI가 원본을 읽고 컴파일하는 지식 베이스다. 소스 요약, 개념 정리, 프로젝트 맥락, 질문, index, log가 여기에 쌓인다.
Output/은 나중에 블로그 글이나 회고글처럼 외부에 공유할 결과물을 두는 곳이다.
이 구조 자체는 어렵지 않다. 오히려 중요한 것은 그 다음이었다.
자료를 많이 모으는 것보다, 왜 모았는지를 남기는 것.
이 관점은 LLM Wiki가 망하는 진짜 이유 영상을 보면서 더 분명해졌다. 폴더 구조와 자동화가 있어도, 그것이 내 삶과 작업 흐름에 연결되지 않으면 결국 지식의 무덤이 될 수 있다. 그래서 나는 이 wiki를 “좋은 자료 모음”이 아니라, 내 학습과 회고를 돕는 시스템으로 만들고 싶었다.
왜 Claude가 아니라 Codex였나
LLM Wiki 관련 자료는 Claude Code를 기준으로 설명되는 경우가 많다. 나도 원래 Claude를 꽤 자주 썼기 때문에 처음에는 Claude로 만드는 흐름이 자연스러울 수 있다.
그런데 막상 오래 쓸 시스템을 생각하니 고민이 생겼다.
최근 Claude를 쓰면서 토큰 부담, 요금 정책 변경, 서버 불안정 같은 부분이 점점 신경 쓰였다. 실제로 Claude가 잘 안 될 때마다 Anthropic의 공식 status page를 확인하게 되었고 실제로 신뢰도도 낮았다.
여기에 2026년 6월 15일부터 Claude Agent SDK, claude -p, Claude Code GitHub Actions, 서드파티 Agent SDK 앱 사용이 별도 월간 credit으로 분리된다는 정책도 확인했다. 이 변화 자체가 나쁘다는 이야기를 하려는 것은 아니다. 다만 장기적으로 반복 실행할 개인 지식 시스템이라면 비용 구조와 안정성도 중요한 기준이 될 수밖에 없었다.
그래서 이번에는 Codex를 중심으로 구축하기로 했다.
참고 자료에서는 Claude Code와 CLAUDE.md를 기준으로 설명했지만, 내 저장소에서는 AGENTS.md를 중심에 두었다. OpenAI의 Codex 소개 글에서도 Codex가 저장소 안의 AGENTS.md를 통해 프로젝트 규칙, 테스트 명령, 작업 방식을 안내받을 수 있다고 설명한다.
결국 내 선택은 “어떤 도구가 더 좋다”는 결론이라기보다 내가 앞으로 더 자주 열고 오래 쓸 도구에 맞추자는 판단이었다.
실제로 만든 것
처음에는 내 맥락부터 정리했다.
나의 핵심 맥락.md에 내가 누구인지, 왜 기록하고 싶은지, 어떤 아웃풋을 만들고 싶은지를 적었다. 이 과정이 생각보다 중요했다. LLM Wiki는 결국 AI가 나를 도와 기록을 정리하는 시스템인데, AI가 “나에게 무엇이 중요한지” 모르면 그저 보기 좋은 요약만 만들 가능성이 높다.
그 다음 루트 AGENTS.md에 나의 맥락과 LLM Wiki 운영 규칙을 넣었다. 그리고 raw/, wiki/, Output/ 폴더를 만들고, 각 폴더에도 역할에 맞는 AGENTS.md를 두었다.
구축하면서 만든 흐름은 대략 이렇다.
raw/에는 원본을 보존한다.wiki/index.md는 전체 목차 역할을 한다.wiki/log.md는 작업 이력을 append-only로 남긴다.- source 문서는 원본별 요약을 담는다.
- concept 문서는 반복 등장하는 개념을 정리한다.
- project 문서는 현재 진행 중인 작업의 맥락과 결정을 담는다.
- question 문서는 아직 확인해야 할 질문을 모은다.
자료 수집은 Obsidian Web Clipper를 기준으로 잡았다. Article, YouTube, Podcast, Book, Research 용도로 템플릿을 나누고, 각 템플릿에 why_collected, personal_connection, key_questions, output_potential 같은 필드를 넣었다.
이 필드들은 번거로워 보이지만, 사실 LLM Wiki에서 가장 중요한 부분이라고 느꼈다. 자료를 모을 때 “왜 이걸 저장했는가”가 빠지면, 나중에 AI가 아무리 잘 정리해도 내 지식이 되기 어렵다.
그래서 앞으로 자료를 넣을 때는 최소한 이 세 가지 질문에는 답하려고 한다.
- 이 글을 왜 캡처했는가?
- 지금 하고 있는 일과 어떻게 연결되는가?
- 이걸로 무엇을 해보고 싶은가?
Codex로 옮기며 헷갈렸던 것
이번 작업에서 가장 헷갈렸던 부분은 skill이었다.
나는 Claude를 주로 써왔고, 참고 자료도 Claude Code 기준이었다. 그래서 처음에는 Claude의 CLAUDE.md와 skill 개념을 그대로 Codex에 옮기면 될 줄 알았다. 그런데 실제로 해보니 비슷해 보이지만 다르게 다뤄야 하는 부분이 있었다.
Claude에서는 CLAUDE.md가 중심 설명서처럼 쓰이고, 그 위에서 반복 작업을 skill로 만들면 된다는 감각이 있었다. Codex에서는 AGENTS.md가 그 역할을 하고, skill도 Codex가 인식할 수 있는 위치와 SKILL.md 구조를 맞춰야 했다.
겉으로 보면 이름만 다른 것처럼 보이지만, 실제로는 “AI에게 반복 작업을 어떻게 맡길 것인가”의 차이에 가까웠다.
결국 이번 구축은 LLM Wiki를 만드는 일이면서 동시에 Codex의 작업 방식을 익히는 과정이기도 했다. /ingest, /query, /lint 성격의 skill을 만들면서 Claude와 Codex간의 Skill을 만들고 사용하는 흐름에 차이를 익히게 됐다. 이런 영역은 아직 확실히 claude가 잘 돼있는 것 같다.
지금은 Graphify를 붙이지 않았다
참고 자료에서는 Graphify도 중요한 확장 도구로 소개된다. Graphify는 Markdown, 코드, 문서 등을 지식 그래프로 바꾸고 AI coding assistant가 그 그래프를 활용할 수 있게 돕는 도구다.
처음에는 나도 바로 붙여야 하나 고민했다. 하지만 지금 내 wiki는 아직 작다. 문서 수가 많지 않은 상태에서는 wiki/index.md와 rg 검색만으로도 충분하다. 지금 Graphify까지 붙이면 오히려 시스템이 과해질 것 같았다.
그래서 Graphify는 당장 설치할 기능이 아니라, 문서가 많아졌을 때 붙일 후보로 남겨두었다. wiki가 커지고, 단순 검색만으로 관련성을 찾기 어려워지는 시점이 오면 그때 다시 도입해보려고 한다.
만들고 나서 든 생각
LLM Wiki를 만들고 나서 가장 크게 느낀 것은, 결국 시스템보다 습관이 중요하다는 점이다.
폴더 구조를 만들고, AGENTS.md를 쓰고, skill을 만들어도 자료를 넣지 않으면 아무 일도 일어나지 않는다. 반대로 자료만 많이 넣고 왜 모았는지 남기지 않으면, 그건 다시 지식의 무덤이 될 가능성이 높다.
그래서 이 시스템의 핵심은 기술적인 자동화보다 “목적 있는 수집”에 있다.
나는 앞으로 좋은 자료를 보면 그냥 저장하는 데서 끝내지 않고, 왜 저장했는지까지 남기고 싶다. 작업하다 막힌 지점도 가능하면 흘려보내지 않고, 나중에 다시 읽을 수 있는 형태로 남기고 싶다. 그렇게 쌓인 기록 중 일부는 블로그 회고글이 되고, 일부는 다음 작업의 참고 자료가 되고, 일부는 내가 어떤 식으로 성장하고 있는지 보여주는 흔적이 될 것이라고 믿고있다.
이번 구축은 완성이라기보다 시작에 가깝다.
그래도 마음에 드는 점은 있다. 이제는 좋은 자료를 봤을 때 “어디에 저장하지?”보다 “이 자료가 내 wiki에서 어떤 의미를 갖게 할까?”를 먼저 생각해보려 한다. 작업이 끝난 뒤에도 “내가 뭘 했더라?”를 처음부터 복원하는 대신, 적어도 복원할 수 있는 자리를 마련해두었다.
1년 뒤 이 시스템이 잘 굴러간다면, 단순히 많은 링크가 모인 저장소가 아니라 내가 배우고, 막히고, 해결하고, 다시 정리한 성장일지가 쌓여 있지 않을까?
물론 난 이 시스템을 완전히 믿지 않는다. LLM은 계속해서 발전해나가고 있고 지금까지 수많은 유행들이 만능 도구로 소개되었다가 소리소문 없이 사라졌다. 이번에 구축한건 나만을 위한 기록 툴을 만들어나간다는 거에 의미를 두려고 한다.
참고 링크
이번 글과 구축 과정에서 직접 참고했거나, 도구 선택의 배경을 설명하기 위해 확인한 링크들이다.
- Karpathy LLM Wiki Idea File: LLM Wiki 패턴의 원형에 가까운 아이디어 파일
- 카파시의 LLM Wiki로 나만의 AI 세컨드 브레인 만들기: Obsidian, Claude Code, Graphify를 연결한 LLM Wiki 구축 참고 영상
- 카파시의 LLM Wiki로 나만의 AI 세컨드 브레인 만들기 - 프롬프트 & 가이드: 실제 구축 프롬프트와 단계 정리
- LLM Wiki가 망하는 진짜 이유: LLM Wiki를 도구가 아니라 목적, 역할, 작업 흐름 안에서 봐야 한다는 관점
- OpenAI - Introducing Codex: Codex와
AGENTS.md의 관계를 확인한 공식 글 - Obsidian Web Clipper: raw 자료 수집 흐름을 만들 때 참고한 공식 페이지
- Graphify: wiki가 커졌을 때 지식 그래프를 붙이기 위한 후보 도구
- Anthropic Claude Status: Claude.ai, API, Claude Code의 uptime과 incident를 확인할 수 있는 공식 status page
- Claude was down - here’s everything we know: 2026년 4월 Claude.ai, API, Claude Code 장애 상황을 사용자 관점에서 정리한 기사
- Use the Claude Agent SDK with your Claude plan: 2026년 6월 15일부터 Agent SDK,
claude -p, Claude Code GitHub Actions, 서드파티 Agent SDK 앱 사용이 별도 월간 credit으로 분리되는 정책 설명 - Anthropic reinstates OpenClaw and third-party agent usage on Claude subscriptions - with a catch: 서드파티 agent 사용이 다시 열렸지만 별도 credit 구조로 바뀐 배경을 다룬 기사
- Anthropic puts Claude agents on a meter across its subscriptions: agent 사용량이 subscription과 분리되어 metered pricing에 가까워지는 흐름을 분석한 기사
- Anthropic tightens Claude limits and OpenAI courts defectors: Claude의 사용 제한 변화와 OpenAI/Codex 쪽 움직임을 함께 다룬 기사