PeekCart를 다시 학습하면서 가장 먼저 확인하고 싶은 것은 개별 기술이 아니라 프로젝트의 진행 순서다.
Redis, Kafka, Kubernetes, MSA 같은 키워드가 많지만, 이 기술들을 각각 따로 보면 왜 필요한지 잘 보이지 않는다. 그래서 0편에서는 코드를 깊게 보기 전에 전체 흐름을 먼저 정리하려고 한다.
이번 학습에서는 PeekCart를 “MSA 프로젝트”로 바로 보지 않고, 모놀리스에서 어떤 문제를 먼저 확인했고 그 문제들이 어떻게 Phase 4의 분리 근거가 되는지 따라가 보려고 한다.

처음에 가정했던 프로젝트 상황
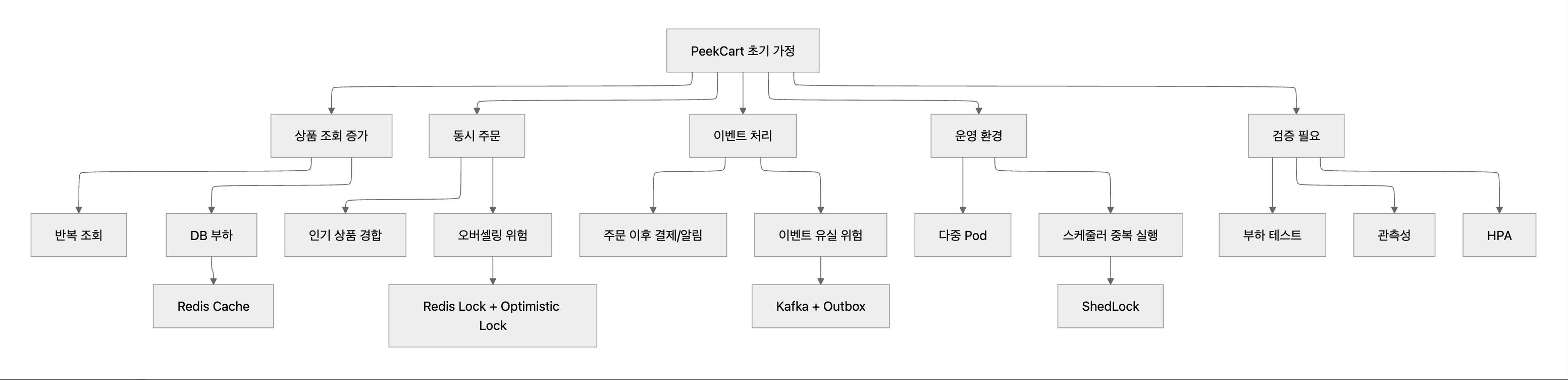
PeekCart는 대용량 트래픽 환경을 고려한 이커머스 플랫폼을 목표로 시작했다. 다만 처음부터 실제 대규모 서비스를 운영한다고 가정한 것은 아니다. 개인 포트폴리오 프로젝트라는 제약 안에서, 이커머스에서 자주 문제가 되는 상황을 단계적으로 재현하고 학습하는 쪽에 가깝다.
초기에 가정했던 상황은 다음과 같다.
- 사용자는 상품을 조회하고 장바구니에 담은 뒤 주문과 결제를 진행한다.
- 상품 조회는 읽기 요청이 많고, 같은 상품 목록과 상세 정보가 반복해서 조회된다.
- 인기 상품은 여러 사용자가 동시에 주문할 수 있고, 이때 재고가 음수가 되면 안 된다.
- 주문 생성 이후 결제, 알림 같은 후속 처리는 주문 트랜잭션과 강하게 묶이면 장애 전파가 커질 수 있다.
- 결제 실패나 결제 타임아웃이 발생하면 주문 상태와 재고를 다시 맞춰야 한다.
- 운영 환경에서는 애플리케이션이 한 대만 떠 있다고 볼 수 없고, 스케줄러나 이벤트 발행도 중복 실행을 고려해야 한다.
- 기능이 동작하는 것만으로는 충분하지 않고, 실제 부하 상황에서 성능과 정합성을 관찰할 수 있어야 한다.
이 가정들을 놓고 보면 처음부터 MSA를 구현하는 것보다 먼저 확인해야 할 것이 많다. 도메인 흐름이 어떻게 이어지는지, 재고 정합성은 어디서 깨질 수 있는지, 이벤트 처리 실패는 어떤 방식으로 복구해야 하는지부터 이해해야 한다.
그래서 PeekCart는 처음에 단일 Spring Boot 애플리케이션으로 시작했다. 단순히 쉬운 길을 선택했다기보다는, 먼저 비즈니스 흐름과 도메인 경계를 관찰할 수 있는 형태를 선택한 것으로 이해하려고 한다.
이번 학습에서 확인하고 싶은 질문
0편에서 내가 잡고 싶은 질문은 세 가지다.
- 왜 처음부터 MSA로 시작하지 않았을까?
- Phase 1~3에서 어떤 문제를 먼저 해결했을까?
- Phase 4에서 분리하려는 경계는 앞 단계에서 어떻게 드러났을까?
이 질문을 들고 문서를 읽으면 기술 스택이 단순한 목록으로 보이지 않는다. Redis는 캐시이기도 하지만 재고 동시성 제어의 도구이기도 하고, Kafka는 비동기 메시지 브로커이기도 하지만 Outbox와 함께 이벤트 유실을 줄이는 장치이기도 하다. Kubernetes도 배포 도구에 그치지 않고 HPA와 관측성 검증의 전제가 된다.
먼저 프로젝트의 목표부터 보기
docs/01-project-overview.md를 보면 PeekCart는 대용량 트래픽 환경을 고려한 이커머스 플랫폼이다.
단순히 회원, 상품, 주문, 결제를 CRUD로 구현하는 것이 아니라, 트래픽 증가 상황에서 성능과 정합성을 어떻게 지킬지까지 다룬다.
여기서 중요한 점은 기술 스택의 나열이 아니다. Java, Spring Boot, Redis, Kafka, Kubernetes를 쓴다는 사실보다, 각 기술이 어느 시점의 문제를 해결하기 위해 들어왔는지를 보는 것이 더 중요하다.
예를 들면 다음처럼 볼 수 있다.
| 기술 / 구조 | 먼저 확인할 질문 |
|---|---|
| 4-Layered + DDD | 모놀리스 안에서 도메인 책임을 어떻게 분리했는가? |
| Redis Cache | 반복 조회가 많은 상품 API에서 DB 부하를 어떻게 줄였는가? |
| Redis Lock + DB Optimistic Lock | 동시 주문에서 오버셀링을 어떻게 막았는가? |
| Kafka + Outbox | DB 저장과 이벤트 발행 사이의 실패를 어떻게 다뤘는가? |
| processed_events | 중복 이벤트 소비를 어떻게 안전하게 처리했는가? |
| ShedLock | 여러 Pod에서 스케줄러가 동시에 실행되는 문제를 어떻게 막았는가? |
| Kubernetes / HPA | 부하가 올라갈 때 애플리케이션이 어떻게 확장되는지 확인했는가? |
| Prometheus / Grafana | 성능과 장애 징후를 어떤 지표로 관찰했는가? |
이 표를 보면 PeekCart의 학습은 “기술을 하나씩 공부한다”보다 “문제와 해결책을 연결해서 본다”에 가깝다.
Phase 1은 왜 모놀리식이었을까
처음부터 MSA로 시작하면 서비스 분리, DB 분리, 배포, 네트워크 통신, 장애 추적 같은 문제가 동시에 생긴다. 그런데 아직 도메인 흐름도 충분히 검증되지 않았다면, 서비스 경계를 나누는 것 자체가 추측에 가까워진다.
그래서 Phase 1에서는 하나의 Spring Boot 애플리케이션 안에서 User, Product, Order, Payment, Notification 도메인을 먼저 구현했다.
다만 내부 구조를 아무렇게나 둔 것은 아니다. 4-Layered + DDD 구조를 사용해 각 도메인의 Presentation, Application, Domain, Infrastructure 책임을 나눴다. 즉 배포 단위는 하나지만, 코드 안에서는 도메인 책임을 관찰할 수 있게 만든 것이다.
Phase 1에서 내가 확인해야 할 것은 “모놀리스냐 MSA냐”가 아니다. 더 중요한 질문은 다음과 같다.
- User, Product, Order, Payment, Notification은 각각 어떤 책임을 갖는가?
- 주문 생성 시 어떤 도메인들이 함께 움직이는가?
- 결제 실패나 타임아웃은 주문 상태와 재고에 어떤 영향을 주는가?
@TransactionalEventListener는 어디까지 편리하고, 어디서 한계를 갖는가?
이 질문들에 답할 수 있어야 Phase 4에서 서비스를 나눌 때도 단순히 패키지를 쪼개는 것이 아니라, 책임과 흐름을 기준으로 나눌 수 있다.
Phase 2는 어떤 불편함에서 출발했을까
Phase 1이 기능 흐름을 완성하는 단계였다면, Phase 2는 이커머스에서 바로 문제가 될 수 있는 부분을 보강하는 단계다.
상품 조회가 많아지면 DB 조회가 반복된다. 그래서 Redis 캐싱이 들어간다.
동시에 여러 사용자가 같은 상품을 주문하면 오버셀링이 생길 수 있다. 그래서 Redis 분산 락과 DB 낙관적 락을 함께 사용한다.
주문 생성 후 결제나 알림 같은 후속 처리를 이벤트로 넘길 때, DB 저장과 이벤트 발행 사이에 실패가 생길 수 있다. 그래서 Kafka와 Outbox 패턴이 들어간다.
Kafka를 사용하면 이벤트가 중복 소비될 수 있다. 그래서 processed_events 테이블을 두고 Consumer 멱등성을 처리한다.
Consumer 처리에 계속 실패하면 메시지를 버릴 수 없다. 그래서 DLQ와 Slack 알림을 둔다.
스케줄러가 여러 Pod에서 동시에 실행될 수 있다. 그래서 ShedLock을 적용한다.
이렇게 보면 Phase 2의 기술들은 “성능 개선용 도구 모음”이 아니다. Phase 1에서 만든 도메인 흐름을 더 안전하게 만들기 위한 보강책이다.
Phase 2를 학습할 때는 각 기술의 사용법보다 아래 질문을 먼저 봐야 한다.
- 이 기술이 없을 때 어떤 장애나 데이터 불일치가 생기는가?
- 이 기술은 문제를 완전히 없애는가, 아니면 특정 리스크를 줄이는가?
- 남는 트레이드오프는 무엇인가?
- Phase 4에서 이 구조는 공통 모듈로 이동할 것인가, 서비스별로 복제될 것인가?
Phase 3는 왜 필요한가
Phase 2까지는 애플리케이션 내부의 설계와 정합성에 초점이 있다.
하지만 실제 운영에 가까워지려면 배포, 모니터링, 부하 테스트가 필요하다. 기능 테스트가 통과한다고 해서 부하 상황에서 성능이 충분하거나, HPA가 의도대로 동작하거나, Kafka Consumer Lag이 안정적으로 돌아온다고 말할 수는 없다.
Phase 3에서는 Kubernetes 배포 구조를 만들고, Prometheus와 Grafana로 메트릭을 수집하고, nGrinder와 k6로 부하 테스트를 수행했다.
여기서 중요한 것은 “Kubernetes를 썼다”가 아니다. 실제로 다음을 확인했다는 점이 중요하다.
- 캐시 적용 전후 TPS가 어떻게 달라졌는가?
- 동시 주문에서 오버셀링이 발생하지 않았는가?
- HPA가 부하 상황에서 Pod를 늘렸는가?
- Kafka Consumer Lag이 peak 이후 정상 상태로 돌아왔는가?
- 관측성 설정이 여러 파일에 흩어졌을 때 어떤 회귀 위험이 생겼는가?
Phase 3는 Phase 4로 가기 전에 현재 구조의 성능과 운영 특성을 관찰하는 단계라고 볼 수 있다.
특히 부하 테스트 결과는 성공과 실패를 함께 봐야 한다. 예를 들어 캐시 적용 후 TPS는 개선되었지만 목표였던 3배에는 미달했다. 동시 주문에서도 오버셀링은 0건이었지만, 1,000 VUser 부하에서 HTTP failure는 높았다. 이것은 프로젝트의 실패라기보다 다음 학습 질문을 만드는 데이터다.
- 병목은 CPU인가, DB 커넥션인가, Redis 락 contention인가?
- HPA는 어느 정도까지 도움을 주고, 어느 지점부터는 한계가 있는가?
- Phase 4에서 Order Service를 분리하면 어떤 병목을 더 명확하게 관찰할 수 있는가?
Phase 4는 무엇을 바꾸는 단계인가
Phase 4는 단순히 폴더를 여러 개로 나누는 작업이 아니다.
지금까지 하나의 애플리케이션과 하나의 DB 안에 있던 경계를 서비스와 DB 단위로 분리하는 단계다.
이때 새로 생기는 질문들이 있다.
- Order Service는 Product 정보를 어떻게 조회할까?
- Payment 실패 시 Order와 Product의 상태는 어떻게 맞출까?
- Gateway는 인증을 어디까지 책임질까?
- 서비스별 DB로 나뉘면 FK 없이 정합성을 어떻게 지킬까?
- 각 서비스의 관측성 설정은 어디에 위치해야 할까?
- Outbox, idempotency, event DTO는 공통 모듈에 둘 수 있을까?
이 질문들은 Phase 4에서 갑자기 생긴 것이 아니다. Phase 1~3에서 이미 Order, Product, Payment, Notification의 책임이 나뉘었고, Kafka와 Outbox, 멱등성, 관측성 계약이 준비되었기 때문에 Phase 4에서 본격적으로 다루게 되는 것이다.
그래서 Phase 4를 공부하기 전에 Phase 1~3을 복습하는 것은 단순한 과거 회고가 아니다. 서비스 경계를 왜 그렇게 나누려는지 이해하기 위한 준비 과정이다.
이번 학습의 방향
앞으로의 학습은 기술별로 흩어져서 보지 않으려고 한다.
각 Phase에서 어떤 문제가 있었고, 그 문제를 해결하기 위해 어떤 설계가 들어왔는지 순서대로 따라가려고 한다.
학습 순서는 다음과 같이 잡는다.
- Phase 1에서 도메인 모델과 기본 비즈니스 흐름을 이해한다.
- Phase 2에서 성능, 정합성, 이벤트 처리 보강을 이해한다.
- Phase 3에서 운영 환경과 부하 테스트 결과를 이해한다.
- 마지막으로 Phase 4에서 어떤 경계를 기준으로 MSA를 분리할지 다시 본다.
이번 0편은 그 출발점이다.
개별 구현을 보기 전에, PeekCart가 왜 모놀리스에서 시작해 MSA로 가는 흐름을 갖게 되었는지 먼저 이해하는 것이 목표다.
다음 글에서 볼 것
다음 글에서는 4-Layered + DDD 구조를 먼저 볼 예정이다.
Phase 1은 모놀리스였지만 내부 구조까지 하나의 덩어리였던 것은 아니다. 각 도메인이 Presentation, Application, Domain, Infrastructure로 나뉘어 있고, 비즈니스 규칙은 Domain 쪽에 모이도록 설계되어 있다.
다음 글의 학습 질문은 다음과 같다.
- 왜 전통적인 Controller-Service-Repository 구조가 아니라 4-Layered + DDD 구조를 선택했을까?
- Application Service와 Domain Entity는 어떤 책임을 나눠 갖는가?
- JPA Entity를 Domain Entity로 함께 쓰는 절충안은 어떤 장단점이 있는가?
- 이 구조가 Phase 4 서비스 분리의 준비가 될 수 있는가?