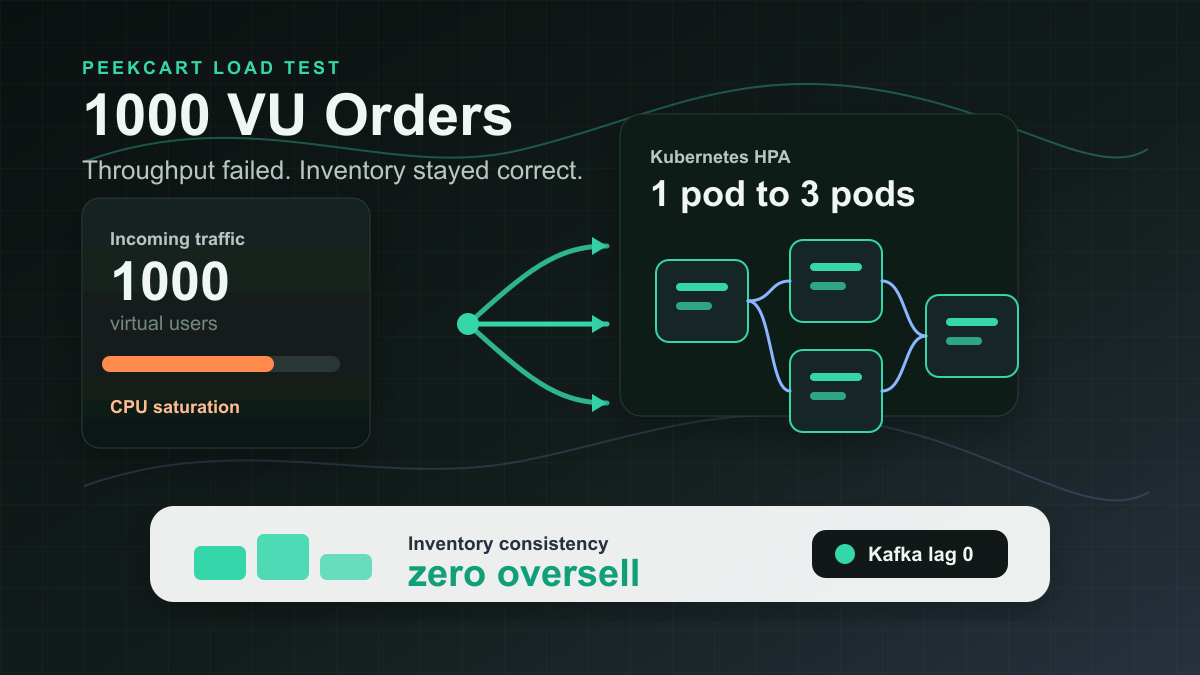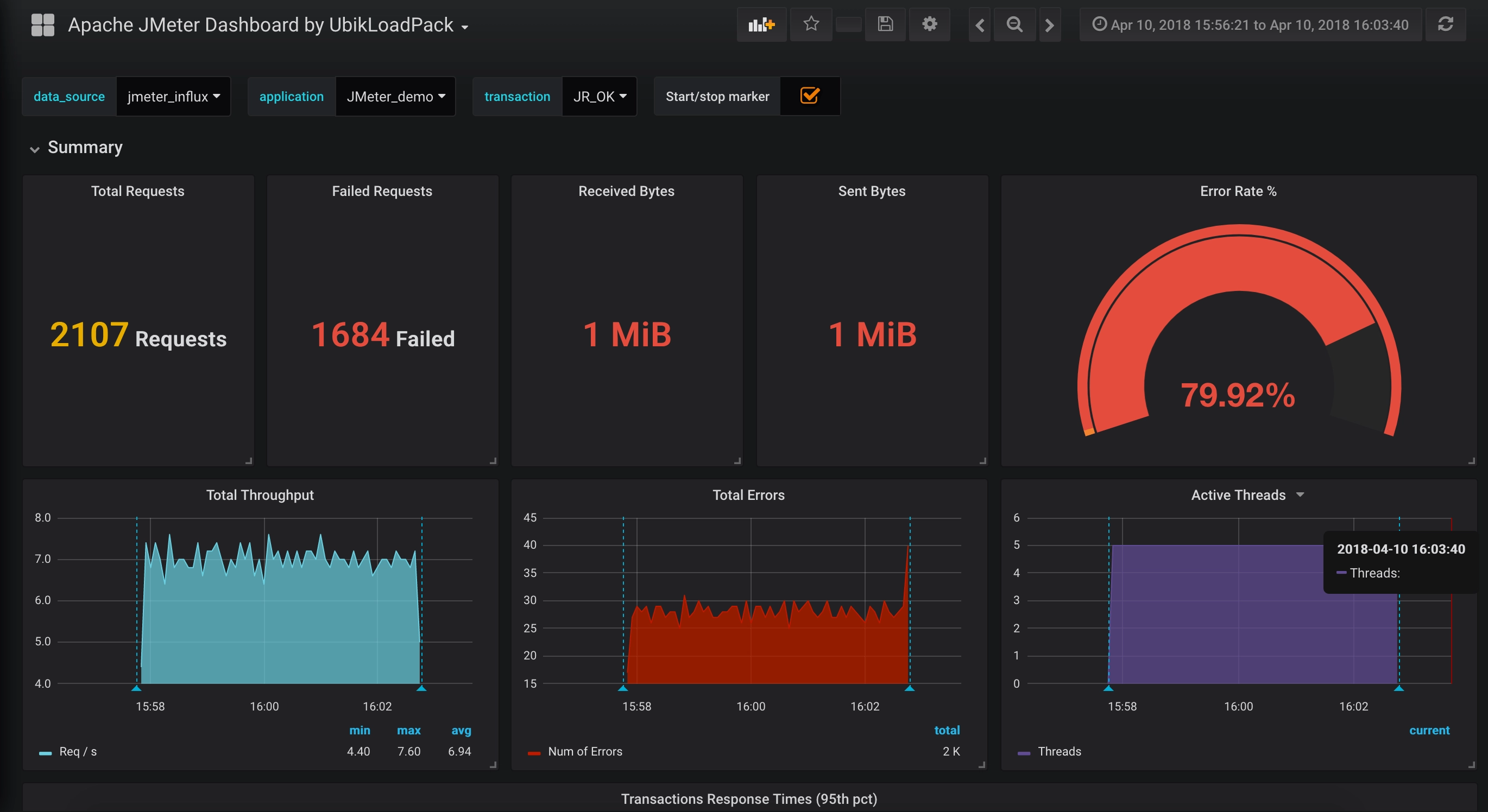
1. 부하 테스트란?
부하 테스트(Load Test) 는
시스템이 예상되는 트래픽을 안정적으로 처리할 수 있는지 검증하는 테스트이다.
단순히 “최대 몇 명까지 버틴다”를 보는 것이 아니다.
더 정확히는
서비스가 실제 환경에서 문제없이 동작하는 범위를 확인하는 것
이 핵심이다.
운영 환경에서는 사용자가 항상 일정하게 들어오지 않는다. 특정 시간대, 이벤트, 티켓팅, 수강신청처럼 트래픽이 몰리는 순간이 있고, 이때 시스템이 어느 정도까지 안정적으로 동작하는지 미리 알아야 한다.
부하 테스트가 답하려는 질문을 조금 더 구체화하면 다음과 같다.
- 현재 서버 구성으로 초당 몇 건 정도의 요청을 안정적으로 처리할 수 있는가?
- 사용자가 늘어날 때 응답 시간은 어느 지점부터 나빠지는가?
- 에러가 발생하기 시작하는 임계점은 어디인가?
- 오토스케일링을 건다면 어떤 지표를 기준으로 삼아야 하는가?
- 성능 병목이 애플리케이션, DB, 네트워크, 외부 API 중 어디에서 발생하는가?
반대로 부하 테스트가 모든 문제를 해결해주는 것은 아니다.
부하 테스트는 관찰과 판단을 위한 데이터를 만들어주는 과정이다. 테스트를 했다고 해서 성능이 자동으로 좋아지는 것은 아니고, 결과를 해석한 뒤 병목을 찾아 개선해야 의미가 있다.
---
2. 부하 테스트를 하는 이유
서비스를 운영하면서 가장 큰 리스크 중 하나는
트래픽 급증으로 인한 서버 장애이다.
예를 들어 다음과 같은 상황에서 트래픽이 짧은 시간에 집중될 수 있다.
- 이벤트 오픈
- 특정 시간대 트래픽 집중
- 마케팅 캠페인
- 티켓팅 폭주
- 대학 수강신청
이런 상황에서 서버가 버티지 못하면 다음 흐름으로 이어질 수 있다.
트래픽 급증 -> 처리 지연 -> 서비스 중단 -> 사용자 이탈 -> 신뢰도 하락부하 테스트는 이런 상황을 운영 당일에 처음 겪지 않기 위해 수행한다.
실제 운영에서는 장애가 발생한 뒤에야 다음 질문을 하게 되는 경우가 많다.
- 정확히 언제부터 느려졌는가?
- 어느 API에서 먼저 병목이 생겼는가?
- 서버 CPU가 부족했는가, DB 커넥션이 부족했는가?
- 네트워크나 외부 API가 원인이었는가?
- 사용자가 몇 명 정도 들어왔을 때부터 문제가 생겼는가?
부하 테스트를 미리 해두면 이런 질문에 대한 기준선을 만들 수 있다.
예를 들어 “현재 구성에서는 100 TPS까지는 P99가 500ms 이하로 유지되지만, 150 TPS부터 P99가 급격히 증가한다”는 식의 기준을 얻을 수 있다. 이 기준이 있어야 서버 증설, 캐시 도입, 쿼리 튜닝, 오토스케일링 같은 결정을 근거 있게 할 수 있다.
---
3. 우리 주변의 실제 사례
3-1. 대학 수강신청: 매 학기 반복되는 피크 트래픽
수강신청 시즌이 되면 학생들 사이에서 “서버 터졌다”는 말이 일상적으로 나온다.
수강신청은 짧은 시간에 많은 학생이 동시에 로그인하고, 강의 목록을 조회하고, 신청 버튼을 누르는 대표적인 피크 트래픽 상황이다.
예시로 다음과 같은 사례들이 있다.
- 명지대(2020년 8월): 수강신청 당일 오전에 L4 스위치 오작동으로 인한 과부하가 발생했고, 수강신청 일정이 다음 날로 연기되었다. 단순 접속 실패를 넘어 일부 수강 내역 처리에도 문제가 발생했다.
- 이화여대: 수강변경 마지막 날 서버가 연속으로 다운되어 변경 기간을 연장했지만, 연장된 시간에도 다시 장애가 발생했다.
- 건국대: 한 학기 동안 여러 차례 수강신청 과정에서 장애가 반복되며 학생들이 정상적으로 수강신청하기 어렵다는 불만이 나왔다.
학교 IT팀은 보통 다음과 같은 방식으로 대응한다.
- 서버 증설
- 장바구니 제도 도입
- 학년별 또는 단과대별 신청 시간 분산
- 대기열 또는 접속 제한
하지만 이런 대응도 결국은 피크 트래픽을 얼마나 정확히 추정하고, 어느 지점에서 시스템이 한계에 도달하는지 아는 것이 전제되어야 한다.
부하 테스트로 한계를 미리 파악하지 못하면, 실제 D-Day에서야 한계점이 드러난다.
3-2. 콘서트·뮤지컬 티켓팅: 예매 시작 직후의 집중 부하
“피켓팅”이라는 말이 생길 정도로, 인기 공연 티켓팅은 예매 시작과 동시에 서버에 엄청난 부하가 몰린다.
티켓팅 서비스에서는 단순 조회만 일어나는 것이 아니다.
- 로그인
- 공연 정보 조회
- 좌석 조회
- 좌석 선점
- 결제 페이지 이동
- 결제 완료
이 과정이 매우 짧은 시간 안에 동시에 발생한다.
예를 들어 인터파크(NOL 티켓)는 예매 오픈 직후 동시 접속이 폭주하면 대기열을 통해 트래픽을 인위적으로 분산한다. 반대로 대기열이나 좌석 잠금 전략이 부족하면 로그인 풀림, 빈 화면, 예매 버튼 누락, 좌석 정합성 문제 같은 사용자 경험 문제가 발생할 수 있다.
핵심은 다음과 같다.
트래픽 분산 전략이 무너지면 단순히 느려지는 것이 아니라, 좌석 선점이나 결제 같은 데이터 정합성까지 흔들릴 수 있다.
3-3. 예스24 서비스 중단: 부하 사례는 아니지만 운영 리스크를 보여주는 사례
2025년 6월 예스24는 랜섬웨어 공격으로 인해 주요 온라인 서비스에 장애를 겪었다.
이 사례는 부하 테스트 실패 사례는 아니다. 원인은 트래픽 폭증이 아니라 보안 사고에 가까웠다.
다만 발표에서 이 사례를 언급하는 이유는, 시스템이 멈췄을 때 어떤 연쇄 영향이 발생하는지 보여주기 때문이다.
- 도서 주문과 결제 기능에 영향
- 티켓 예매 서비스에 영향
- eBook 등 일부 서비스 이용에 영향
- 사용자 문의, 환불, 일정 조정 등 운영 대응 증가
공개 보도 기준으로 2025년 6월 9일 장애가 발생했고, 6월 13일 도서·티켓 등 일부 서비스가 재개되었다. 따라서 “10일간 전면 중단”처럼 단정하기보다는, 랜섬웨어로 주요 서비스가 며칠간 중단되고 순차 복구된 사례로 이해하는 것이 정확하다.
이 사례는 부하 테스트의 직접 사례는 아니지만, 다음 메시지를 보강한다.
시스템 중단은 기술 문제에서 끝나지 않고, 주문·예매·고객 응대·신뢰도까지 연쇄적으로 영향을 준다.
3-4. 사례에서 가져갈 공통 교훈
위 사례들은 원인과 맥락은 다르지만, 운영 관점에서는 몇 가지 공통점을 가진다.
첫째, 장애는 사용자가 가장 많이 몰리는 순간에 드러나는 경우가 많다. 평소에는 문제가 없어 보이던 시스템도 피크 트래픽에서는 전혀 다른 양상을 보일 수 있다.
둘째, 단순히 서버가 느려지는 것에서 끝나지 않는다. 수강신청에서는 신청 결과의 일관성, 티켓팅에서는 좌석 선점과 결제 정합성, 커머스에서는 주문과 환불 같은 비즈니스 흐름 전체가 영향을 받는다.
셋째, 장애가 발생한 뒤 대응하면 이미 사용자 신뢰를 잃은 뒤일 수 있다. 부하 테스트는 장애를 완전히 없애기 위한 도구라기보다는, 적어도 “어느 구간부터 위험한지”를 사전에 알고 대응 기준을 세우기 위한 도구이다.
---
4. 왜 그냥 서버를 크게 쓰지 않을까?
트래픽이 문제라면 “그냥 서버를 크게 쓰면 되는 것 아닌가?”라고 생각할 수 있다.
이론적으로는 가능하지만, 현실에서는 비용 문제가 발생한다.
- 인프라 비용은 트래픽 대비 계속 증가한다.
- 피크 시간 기준으로 과하게 구성하면 대부분의 시간에는 자원이 낭비된다.
- 너무 작게 구성하면 장애 위험이 커진다.
- 오토스케일링 기준점도 결국 측정값이 있어야 설정할 수 있다.
따라서 목표는 다음과 같다.
무조건 큰 서버
-> 비용 낭비 가능성 큼
최소 비용으로 안정적인 성능 확보
-> 운영 관점에서 현실적인 목표부하 테스트는
터지지 않는 최소 비용 구조를 찾기 위한 과정
이라고 볼 수 있다.
여기서 중요한 것은 “최소 비용”이 단순히 서버 비용을 아끼자는 의미만은 아니라는 점이다.
운영 비용에는 다음 요소가 함께 포함된다.
- 서버와 네트워크 비용
- 장애 대응에 드는 인력 비용
- 장애로 인한 매출 손실
- 사용자 신뢰도 하락
- 장애 이후 보상과 커뮤니케이션 비용
따라서 부하 테스트는 인프라 비용을 줄이는 활동이면서 동시에, 장애 비용을 줄이는 활동이기도 하다.
---
5. 테스트 유형 비교
성능 테스트 안에는 여러 유형이 있다. 이번 발표의 중심은 Load Test이지만, 다른 테스트와의 차이를 함께 알아두면 좋다.
종류 목적 활용 시점
| Load Test | 예상 트래픽에서 안정적으로 동작하는지 확인 | 이번 발표의 핵심 |
| Stress Test | 한계치를 초과했을 때 시스템이 어떻게 무너지는지 확인 | 내구 한계 파악 |
| Spike Test | 갑작스러운 트래픽 폭증에 버티는지 확인 | 순간 급증 대응 확인 |
| Soak Test | 장시간 운영 시 메모리 누수나 성능 저하를 발견 | 장기 안정성 검증 |
k6에서는 이런 테스트 유형을 options의 시나리오 설정으로 표현할 수 있다.
예를 들어 Load Test는 일정한 VU를 유지하는 방식으로, Spike Test는 짧은 시간에 VU를 급격히 올렸다가 내리는 방식으로 표현할 수 있다.
각 테스트 유형은 관찰하려는 질문이 다르다.
Load Test가 보는 것
Load Test는 예상 트래픽 수준에서 서비스가 안정적으로 동작하는지 확인한다.
예를 들어 “평소 피크 시간에 동시 사용자가 1,000명 정도 들어온다”면, 이 수준의 부하를 재현했을 때 TPS, P95/P99 Latency, Error Rate가 목표 범위 안에 들어오는지를 본다.
Stress Test가 보는 것
Stress Test는 예상보다 더 큰 부하를 걸어 시스템이 어디서부터 무너지는지 확인한다.
목적은 장애를 일부러 만드는 것에 가깝다. 어느 지점에서 TPS가 정체되는지, P99가 폭증하는지, 5xx나 Timeout이 발생하는지를 확인한다.
Spike Test가 보는 것
Spike Test는 순간적으로 트래픽이 튀는 상황을 확인한다.
예를 들어 이벤트 오픈 직후, 티켓팅 시작 직후처럼 짧은 시간에 사용자가 몰렸다가 빠지는 상황이다. 이때는 평균 부하보다 순간 부하 대응 능력이 중요하다.
Soak Test가 보는 것
Soak Test는 장시간 운영 중 문제가 생기는지 확인한다.
짧은 테스트에서는 괜찮아 보여도, 몇 시간 이상 돌렸을 때 메모리 누수, 커넥션 누수, 로그 적재 문제, 캐시 오염, GC 증가 같은 문제가 드러날 수 있다.
---
6. VU(Virtual User): 가상 사용자
지표를 이해하기 전에 VU 개념이 먼저 필요하다.
VU = 사용자 행동을 반복 실행하는 시뮬레이션된 사용자 1명
예를 들어 VU 50명은 최대 50개의 사용자 시나리오가 동시에 실행되는 상황으로 이해할 수 있다.
k6에서는 코드로 이렇게 표현한다.
export const options = {
vus: 50, // 가상 사용자 50명
duration: '30s' // 30초 동안 유지
};여기서 중요한 점은, VU라는 개념이 모든 도구에서 똑같은 실행 구조를 의미하지는 않는다는 것이다.
도구별 실행 흐름
k6
Scenario -> VU -> k6 Runtime -> Targetk6에서는 사용자의 행동 흐름을 시나리오로 작성하고, VU가 그 시나리오를 반복 실행한다.
다만 VU 1명이 OS Thread 1개로 그대로 매핑되는 구조는 아니다. 여러 VU를 k6 Runtime이 효율적으로 실행하고, 그 결과로 대상 서버에 요청을 보낸다고 이해하면 된다.
JMeter
Scenario -> Thread Group -> Thread -> TargetJMeter에서는 Thread Group이 동시 사용자 그룹에 가깝고, Thread가 실제 요청을 실행하는 작업자 단위다.
그래서 JMeter를 설명할 때는 “Thread 기반으로 동시 사용자를 표현한다”고 말할 수 있다.
nGrinder
Scenario -> Controller -> Agent -> Thread -> TargetnGrinder는 Controller가 테스트를 지시하고, Agent가 실제 부하를 생성한다.
Agent 안에서 Thread들이 요청을 실행하기 때문에, 대규모 부하를 여러 Agent로 분산시키기 좋다.
정리하면 다음과 같다.
- k6는 VU를 k6 Runtime이 실행한다.
- JMeter는 Thread Group과 Thread 중심으로 이해한다.
- nGrinder는 Controller-Agent 구조 위에서 Thread가 요청을 실행한다.
용어 정리
용어 의미
| VU | 실제 사용자가 아니라, 사용자 행동을 흉내 내는 가상 사용자 |
| Thread | 요청을 실제로 실행하는 작업자 단위 |
| Agent | 부하를 대신 만들어주는 서버. 여러 대를 사용해 트래픽을 나누어 보낼 수 있음 |
쉽게 보면 VU는 “사용자 역할”에 가깝고, Thread는 “작업자”에 가깝다.
Thread 기반 테스트와 VU 기반 테스트
부하 테스트 도구를 비교할 때 자주 나오는 차이가 Thread 기반 모델과 VU 기반 모델이다.
Thread 기반 모델은 동시 사용자를 Thread 중심으로 표현한다. JMeter가 대표적이다. 사용자가 늘어나면 그만큼 실행 Thread가 늘어나는 구조에 가깝기 때문에, “사용자 1명 = 작업자 1명”처럼 직관적으로 이해하기 쉽다.
장점은 다음과 같다.
- 실행 구조가 직관적이다.
- 각 사용자가 독립적으로 실행되는 느낌이 강하다.
- 오래된 도구와 자료가 많아 학습 자료를 찾기 쉽다.
- GUI 기반 도구와 결합되면 비개발자도 접근하기 쉽다.
단점도 있다.
- 동시 사용자가 많아질수록 Thread 수가 늘어난다.
- Thread마다 메모리 비용이 발생한다.
- 많은 Thread가 동시에 동작하면 컨텍스트 스위칭 비용이 커질 수 있다.
- 같은 장비에서 만들 수 있는 부하 규모가 상대적으로 제한될 수 있다.
반면 k6 같은 VU 기반 모델은 VU를 OS Thread와 1:1로 매핑하지 않는다. VU는 “사용자 행동을 반복하는 논리적 단위”이고, 실제 실행은 k6 Runtime이 효율적으로 처리한다.
장점은 다음과 같다.
- 같은 장비에서 더 많은 가상 사용자를 만들기 유리하다.
- 코드 기반 테스트와 잘 맞는다.
- CLI 실행과 CI/CD 연동이 자연스럽다.
- 테스트 스크립트를 Git으로 관리하고 리뷰하기 쉽다.
주의할 점도 있다.
- VU가 실제 OS Thread 하나라는 뜻은 아니다.
- JMeter의 Thread 수와 k6의 VU 수를 단순히 같은 의미로 비교하면 안 된다.
- 도구마다 스케줄링 방식, 런타임, 메트릭 계산 방식이 다르기 때문에 결과를 해석할 때 실행 모델을 함께 봐야 한다.
정리하면 다음과 같다.
구분 Thread 기반 테스트 VU 기반 테스트
| 대표 도구 | JMeter, nGrinder | k6 |
| 핵심 단위 | Thread | VU |
| 이해 방식 | 사용자 1명과 작업자 1명을 가깝게 매핑 | 사용자 행동을 논리적 VU로 표현 |
| 장점 | 직관적, 오래된 자료 많음, GUI와 결합 쉬움 | 가볍고 코드 기반 관리에 유리, 대규모 VU에 효율적 |
| 단점 | Thread 증가에 따른 메모리와 컨텍스트 스위칭 비용 | VU와 OS Thread를 혼동하면 해석 오류 가능 |
VU와 실제 사용자는 완전히 같지 않다
VU는 실제 사용자를 흉내 내는 단위이지만, 실제 사용자와 완전히 같지는 않다.
실제 사용자는 다음과 같은 행동을 한다.
- 페이지를 읽느라 잠시 멈춘다.
- 버튼을 누르기 전에 고민한다.
- 같은 API를 반복 호출하지 않고 여러 화면을 이동한다.
- 일부 사용자는 중간에 이탈한다.
따라서 부하 테스트 시나리오를 만들 때는 단순히 요청을 빠르게 반복하는 것보다, 실제 사용자 행동에 가까운 흐름을 구성하는 것이 중요하다.
예를 들어 다음 두 시나리오는 의미가 다르다.
나쁜 예:
상품 조회 API만 쉬지 않고 반복 호출
더 현실적인 예:
로그인 -> 상품 목록 조회 -> 상품 상세 조회 -> 장바구니 담기 -> 결제 시도 -> 잠시 대기여기서 “잠시 대기”에 해당하는 시간이 Think Time이다. 사용자가 화면을 읽거나 다음 행동을 선택하는 시간을 시나리오에 반영해야 실제에 가까운 TPS를 얻을 수 있다.
---
7. 부하 테스트 핵심 지표 3가지
부하 테스트 결과를 볼 때는 적어도 다음 세 가지 지표를 함께 봐야 한다.
- 처리량(Throughput, TPS)
- 지연 시간(Latency, 특히 P95/P99)
- 요청 실패율(Error Rate)
---
7-1. 처리량(Throughput, TPS)
처리량은 시스템이 단위 시간 동안 처리할 수 있는 요청 수를 의미한다.
일반적으로 TPS(Transactions Per Second)라는 단위를 사용한다.
TPS 계산 감각
TPS ~= VU 수 / (응답시간 + 대기시간)
예) VU=100, 응답시간=200ms, 대기시간=800ms
-> TPS ~= 100 / 1.0 = 100 TPS실제 TPS는 다음 요소에 함께 영향을 받는다.
- VU 수
- 응답시간
- 사용자 행동 사이의 대기시간
- 시나리오 구조
- 서버 처리 능력
변화 패턴
일반적인 부하 테스트에서는 다음 패턴이 나타난다.
- 가상 사용자(VU)가 증가하면 TPS도 증가한다.
- 하지만 어느 순간부터 TPS 증가가 멈춘다.
- 이 지점이 시스템의 최대 처리 용량, 즉 Capacity에 가까운 구간이다.
TPS가 더 이상 증가하지 않는데 VU만 계속 늘리면, 요청은 더 많이 들어오지만 시스템은 더 많이 처리하지 못한다. 이때부터 지연 시간과 실패율을 함께 봐야 한다.
TPS와 RPS
문서나 도구에 따라 TPS 대신 RPS(Requests Per Second)라는 표현을 쓰기도 한다.
- RPS: 초당 HTTP 요청 수
- TPS: 초당 트랜잭션 수
단순 API 테스트에서는 둘을 거의 비슷하게 쓰기도 한다. 하지만 하나의 트랜잭션이 여러 요청으로 구성되는 경우에는 구분이 필요하다.
예를 들어 “상품 구매 1건”이라는 트랜잭션은 내부적으로 다음 요청들로 구성될 수 있다.
상품 조회 -> 재고 확인 -> 쿠폰 검증 -> 결제 요청 -> 주문 생성이 경우 HTTP 요청 수는 여러 개지만, 비즈니스 트랜잭션은 구매 1건이다.
발표에서는 이해를 쉽게 하기 위해 TPS를 “초당 처리량”이라는 넓은 의미로 사용한다.
TPS만 높다고 좋은 것은 아니다
TPS가 높아도 Latency가 너무 높거나 Error Rate가 증가하면 좋은 결과라고 보기 어렵다.
예를 들어 다음 두 결과를 비교해보자.
결과 TPS P99 Latency Error Rate
| A | 500 TPS | 300ms | 0% |
| B | 800 TPS | 5s | 8% |
B는 처리량만 보면 더 좋아 보이지만, 사용자 경험과 안정성까지 보면 A가 더 좋은 결과일 수 있다.
그래서 TPS는 반드시 Latency, Error Rate와 함께 해석해야 한다.
---
7-2. 지연 시간(Latency)
Latency는 요청을 보낸 뒤 응답을 받을 때까지 걸리는 시간이다.
부하 테스트에서 Latency를 볼 때 중요한 점은 평균값만 보면 안 된다는 것이다.
평균값뿐 아니라 P95, P99를 함께 봐야 한다.
P95 / P99란?
지표 의미 활용
| P95 | 100개의 요청 중 95개는 이 시간 이하에 응답 | 대부분의 사용자 경험 파악 |
| P99 | 100개의 요청 중 99개는 이 시간 이하에 응답 | 최악에 가까운 경험, 병목 구간, 장애 직전 신호 감지 |
실제 사용자 경험은 평균보다 느린 요청이 좌우하는 경우가 많다.
평균의 함정
평균만 보면 안 되는 이유는 일상적인 예시로도 이해할 수 있다.
직원 9명이 각각 연봉 3천만 원을 받고, CEO 1명이 30억 원을 번다고 해보자.
이 회사의 평균 연봉은 약 3억 원이 된다.
하지만 대다수 직원의 실제 상황은 3천만 원이다. 평균 하나가 현실을 가려버린다.
Latency도 똑같다.
요청 99개 -> 100ms
요청 1개 -> 3,000ms
평균 = 약 130ms겉보기에는 빠른 서비스처럼 보이지만, 일부 사용자는 매우 느린 경험을 한다.
정리하면 다음과 같다.
평균은 “전체적인 속도”를 보여주지만, P95와 P99는 “사용자가 실제로 겪는 느림”을 보여준다.
부하 증가 시 Latency 변화 패턴
구간 평균 P95 P99
| 초기 | 안정 | 안정 | 안정 |
| 임계점 도달 | 거의 유지 | 서서히 증가 | 급격히 증가 |
| 한계 초과 | 약간 증가 | 크게 증가 | 폭발적으로 증가 |
왜 이런 패턴이 나타날까?
대부분의 서버는 내부적으로 Queue를 기반으로 요청을 처리한다. 처리 한계를 넘으면 요청이 바로 처리되지 못하고 대기열에 쌓인다. 이때 일부 요청의 대기 시간이 급격히 길어지고, 그 결과 P99가 먼저 흔들린다.
1단계 초기 -> 안정적인 응답
2단계 임계점 -> 요청 대기 발생
3단계 한계 초과 -> 지연 시간 급증Percentile을 볼 때 주의할 점
P95, P99는 평균보다 사용자 경험을 더 잘 보여주지만, 이것도 무조건 완벽한 지표는 아니다.
예를 들어 요청 수가 너무 적으면 P99가 안정적인 의미를 갖기 어렵다. 요청이 100개밖에 없다면 P99는 거의 가장 느린 요청 1개에 의해 결정된다. 따라서 Percentile 지표는 충분한 요청 수와 함께 봐야 한다.
또한 전체 API를 하나로 묶은 P99만 보면 어떤 API가 느린지 알기 어렵다. 실제 분석에서는 다음처럼 나누어 보는 것이 좋다.
- 전체 요청의 P95/P99
- API 엔드포인트별 P95/P99
- 성공 요청과 실패 요청을 분리한 Latency
- DB 쿼리, 외부 API 호출, 캐시 접근 시간 등 내부 지표
부하 테스트 결과에서 “P99가 높다”는 것은 결론이 아니라 분석의 시작점이다. 그 다음에는 어떤 요청이 느린지, 왜 느린지 좁혀가야 한다.
---
7-3. 요청 실패율(Error Rate)
Error Rate는 실패한 요청의 비율 또는 개수이다.
부하 테스트에서 체크해야 할 대표적인 항목은 다음과 같다.
- HTTP 5xx
- Timeout
- Connection 실패
에러가 발생하기 시작했다는 것은 시스템이 안정 구간을 넘어섰다는 신호일 수 있다.
에러가 발생하는 시점 = 시스템 한계에 도달했거나 이미 초과한 시점
으로 볼 수 있다.
HTTP 200이어도 실패일 수 있다
Error Rate를 볼 때 HTTP 상태 코드만 보면 부족할 수 있다.
예를 들어 서버가 HTTP 200을 반환했지만, 응답 본문이 다음과 같다면 비즈니스 관점에서는 실패일 수 있다.
{
"success": false,
"message": "재고가 부족합니다"
}물론 재고 부족이 정상 비즈니스 흐름이라면 실패로 보지 않을 수도 있다. 반대로 티켓팅이나 결제 과정에서 좌석 선점 실패, 결제 검증 실패, 주문 생성 실패가 비정상적으로 증가한다면 HTTP 200이어도 문제가 될 수 있다.
따라서 부하 테스트에서는 다음 두 가지를 함께 봐야 한다.
- 기술적 실패: 5xx, Timeout, Connection Error
- 비즈니스 실패: 응답은 왔지만 기대한 상태가 아닌 경우
k6에서는 check를 사용해 응답 상태 코드뿐 아니라 응답 내용까지 검증할 수 있다.
---
8. 부하 테스트의 핵심 개념: 전환 구간 찾기
부하 테스트의 목적은 단순한 수치 측정이 아니다.
시스템이 안정적으로 유지되는 최대 구간을 찾는 것이 핵심이다.
이상적인 관찰 흐름은 다음과 같다.
- 사용자 증가 -> TPS 증가
- 어느 순간 -> TPS 정체(Capacity 도달)
- 이후 -> Latency 증가, 특히 P99가 먼저 흔들림
- 더 이후 -> Error 발생
부하 테스트에서 찾고 싶은 것은 “장애가 난 지점”만이 아니다.
운영 관점에서 더 중요한 것은 다음 지점이다.
장애가 나기 전, 안정적으로 운영할 수 있는 마지막 구간
이 전환 구간을 알아야 다음 의사결정을 할 수 있다.
- 현재 서버 스펙으로 감당 가능한 트래픽 범위
- 오토스케일링을 시작해야 하는 기준
- 알림을 걸어야 하는 임계치
- 성능 개선이 필요한 병목 지점
그래프를 읽는 순서
부하 테스트 결과를 볼 때는 보통 다음 순서로 보는 것이 좋다.
- VU 또는 요청량이 의도한 대로 증가했는지 확인한다.
- TPS가 어느 지점까지 증가하는지 확인한다.
- TPS가 정체되는 지점을 찾는다.
- 같은 구간에서 P95/P99 Latency가 어떻게 변하는지 본다.
- Error Rate가 언제부터 발생하는지 확인한다.
- 서버 자원 지표(CPU, Memory, DB Connection, Network)를 함께 본다.
이 순서로 보면 “사용자를 늘렸더니 느려졌다”에서 끝나지 않고, 어느 지점에서 어떤 지표가 먼저 무너졌는지 볼 수 있다.
---
9. 테스트 환경 구성 원칙
부하 생성 서버는 반드시 분리
부하 테스트를 할 때는 부하를 만드는 서버와 측정 대상 서버를 분리하는 것이 좋다.
[Load Generator] -> [Target Server]
k6 실행 Spring Boot 실행이유
부하 생성도 CPU와 네트워크 자원을 사용한다.
같은 서버에서 k6와 Spring Boot를 동시에 실행하면 다음 문제가 생긴다.
- k6가 CPU를 쓰는 만큼 Spring Boot가 사용할 수 있는 자원이 줄어든다.
- 측정된 Latency에 실제 처리 지연과 부하 생성기의 자원 경합이 함께 섞인다.
- 서버가 원래 느린 것인지, k6 때문에 느려진 것인지 구분하기 어렵다.
따라서 올바른 구조는 다음과 같다.
부하 생성 서버 -> 네트워크 요청 -> 측정 대상 서버이렇게 해야 순수한 서버 성능에 가까운 값을 측정할 수 있고, 결과 신뢰도를 확보할 수 있다.
10. 부하 테스트 도구 비교
대표적인 부하 테스트 도구로 k6, JMeter, nGrinder를 비교할 수 있다.
한눈에 보는 비교표
항목 k6 JMeter nGrinder
| 작성 방식 | JavaScript 코드 | GUI(XML 저장) | 웹 UI + Groovy 스크립트 |
| 기반 언어 | Go 런타임 | Java(JVM) | Java + Groovy |
| 실행 방식 | CLI | GUI / CLI | 웹 UI(Controller-Agent) |
| 메모리 사용량 | VU당 약 1~5MB 수준 가능(단순 테스트 기준) | 상대적으로 높음 | JVM 기반, Agent 단위로 메모리 소비 |
| 동시 사용자 처리 | 대규모 VU 처리에 유리 | Thread 기반이라 상대적으로 제약이 큼 | Agent 분산으로 확장 가능 |
| 동시성 모델 | k6 Runtime. VU와 OS Thread가 1:1 매핑되지 않음 | Thread per VU | Thread per VU, Agent별 분산 |
| 분산 부하 | k6 Operator(Kubernetes) 등 별도 구성 | JMeter 서버 분산 | Controller-Agent 네이티브 지원 |
| 프로토콜 | HTTP, WebSocket, gRPC 중심 | JDBC, FTP, JMS, SMTP, LDAP 등 광범위 | HTTP 중심 |
| CI/CD 연동 | CLI 친화적 | 별도 설정 필요 | 가능하지만 번거로울 수 있음 |
| Git 협업 | 코드 기반이라 유리 | XML 기반이라 변경 추적 어려움 | 코드 기반 가능, 웹 UI 중심 |
| 시각화 | Grafana + Prometheus / InfluxDB 연동 | HTML 리포트 + 플러그인 | 웹 UI 내장, CSV/tgz 다운로드 |
| 학습 곡선 | JavaScript를 알면 빠름 | GUI는 쉽지만 고급 기능은 플러그인 의존 | Controller-Agent 설정 때문에 진입장벽 있음 |
| 첫 출시 | 2017년 | 1998년 | 2011년, 네이버 사내 도구에서 오픈소스화 |
표의 값은 절대적인 우열이라기보다, 어떤 상황에 어떤 도구가 더 잘 맞는지를 보기 위한 기준이다.
도구를 비교할 때는 “어떤 도구가 제일 좋은가?”보다 다음 질문이 더 중요하다.
- 누가 테스트를 작성하는가? 개발팀인가, QA팀인가?
- 테스트 시나리오를 Git으로 관리해야 하는가?
- CI/CD 파이프라인에 넣을 것인가?
- HTTP API만 보면 되는가, DB나 메시지 큐도 직접 테스트해야 하는가?
- 단일 머신 부하로 충분한가, 분산 부하가 필요한가?
- 결과를 어떤 방식으로 공유하고 시각화할 것인가?
---
11. k6: Performance as Code
k6의 핵심 철학은 Performance as Code이다.
테스트 시나리오를 코드로 작성하고, 일반 애플리케이션 코드처럼 Git으로 관리하며 코드 리뷰를 거친다는 접근이다.
왜 가벼운가?
k6는 Go 언어 런타임 기반으로 동작한다.
JMeter처럼 VU 1명당 OS Thread 1개를 그대로 띄우는 방식보다 대규모 테스트에 효율적인 구조를 가진다.
단순 테스트 기준으로 k6는 VU 1명당 약 1~5MB 수준의 메모리를 사용할 수 있다고 알려져 있다. 다만 정확한 생성 가능 부하는 다음 요소에 따라 달라진다.
- 스크립트 복잡도
- 응답 본문 처리 여부
- 체크와 메트릭 수집 방식
- 부하 생성 서버의 CPU, 메모리, 네트워크 성능
장점
- JavaScript 기반 코드 방식이라 백엔드/프론트엔드 개발자 모두 접근하기 쉽다.
- Git 관리, 코드 리뷰, CI/CD 파이프라인 연동이 자연스럽다.
- CLI 기반이라 자동화하기 좋다.
- Grafana, Prometheus, InfluxDB 등과 연동해 메트릭 시각화가 강력하다.
단점
- GUI가 없어 비개발자에게는 진입장벽이 있을 수 있다.
- HTTP/HTTPS, WebSocket, gRPC 중심이라 JDBC나 SMTP 같은 프로토콜 테스트에는 약하다.
- JMeter에 비하면 축적된 레거시 자료와 플러그인 생태계가 작다.
언제 적합한가?
- 개발팀이 직접 성능 테스트를 작성하고 관리할 때
- CI/CD 파이프라인에 부하 테스트를 통합하고 싶을 때
- HTTP API 중심의 모던 웹 서비스를 테스트할 때
- 개인 학습이나 사이드 프로젝트에서 빠르게 시작하고 싶을 때
---
12. JMeter: 레거시 기업 표준
JMeter는 1998년부터 사용된 오래된 부하 테스트 도구이다.
핵심 접근은 GUI로 테스트 플랜을 구성할 수 있다는 점이다.
JMeter의 강점: 광범위한 프로토콜 지원
JMeter는 HTTP뿐 아니라 다음과 같은 다양한 프로토콜을 지원한다.
- JDBC
- FTP
- JMS
- SMTP
- LDAP
- SOAP
여러 시스템이 얽힌 엔터프라이즈 환경에서는 이 점이 큰 장점이 된다.
장점
- GUI 클릭으로 테스트를 구성할 수 있어 QA 팀이나 비개발자도 접근하기 쉽다.
- 20년 이상 축적된 자료, 플러그인, 커뮤니티가 있다.
- HTTP 외에도 DB, 메시지 큐, 메일 서버 등 다양한 프로토콜을 테스트할 수 있다.
- 상세한 HTML 리포트를 제공한다.
단점
- JVM 기반과 Thread 모델 특성상 같은 부하를 만들 때 더 많은 자원이 필요할 수 있다.
- 테스트 플랜이 XML로 저장되어 Git에서 변경 사항을 읽기 어렵다.
- GUI는 테스트 설계에는 편하지만, 실제 대규모 부하 생성은 CLI 모드가 권장된다.
- 핵심 기능이 플러그인으로 분산되어 있어 처음 사용하는 사람이 어떤 플러그인을 써야 할지 헷갈릴 수 있다.
언제 적합한가?
- DB, 메시지 큐 등 비 HTTP 프로토콜까지 테스트해야 할 때
- QA 팀이 GUI 기반으로 작업하는 조직일 때
- 이미 JMeter 테스트 플랜과 운영 경험이 많이 쌓여 있을 때
- 레거시 시스템이나 엔터프라이즈 환경을 테스트할 때
---
13. nGrinder: 대규모 분산 테스트
nGrinder는 네이버가 사내에서 쓰던 도구를 2011년 오픈소스로 공개한 부하 테스트 도구이다.
핵심 차별점은 Controller + Agent 구조이다.
Controller-Agent 분산 구조
[Controller (웹 UI)]
|
+--> [Agent 1] -> Target Server
+--> [Agent 2] -> Target Server
+--> [Agent N] -> Target ServerController는 테스트를 지시하고, Agent는 실제 부하를 생성한다.
여러 대의 Agent 머신에 부하 생성을 분산시킬 수 있어, 단일 서버로는 만들기 어려운 대규모 트래픽을 만들 수 있다.
장점
- 분산 부하 테스트가 네이티브로 지원된다.
- 웹 UI에서 테스트 실행, 모니터링, 결과 확인을 한 곳에서 할 수 있다.
- 결과 리포트를 CSV, tgz 등으로 다운로드할 수 있다.
- Groovy 또는 Jython 스크립트로 시나리오를 작성할 수 있다.
단점
- Controller와 Agent를 각각 세팅해야 하므로 초기 설정이 복잡하다.
- k6보다 처음 시작하기 어렵다.
- 커뮤니티 규모는 k6나 JMeter 대비 작다.
- UI와 운영 방식이 다소 전통적인 형태에 가깝다.
언제 적합한가?
- 단일 머신으로 만들 수 없는 대규모 부하가 필요할 때
- 사내에서 여러 팀이 함께 쓰는 부하 테스트 플랫폼을 구축하고 싶을 때
- 분산 환경에서 대형 서비스를 운영하고 있을 때
---
14. 요약: 어느 도구를 언제 쓰나?
상황 추천 도구
| 일반적인 웹 API 부하 테스트 + CI/CD 자동화 | k6 |
| DB·메일·메시지 큐까지 테스트 + GUI 기반 작업 | JMeter |
| 대규모 분산 부하 + 사내 공용 테스트 플랫폼 | nGrinder |
| 개인 학습 / 사이드 프로젝트 | k6 |
---
15. 정말 “툴은 중요하지 않을까”?
“툴은 중요하지 않고 개념만 알면 된다”는 말은 절반만 맞다.
맞는 이유
핵심은 지표 해석 능력에 있다.
어떤 도구를 사용하더라도 TPS, Latency, Error Rate를 읽고 해석할 수 있으면 부하 테스트의 목적은 어느 정도 달성된다.
틀린 이유
하지만 협업, 자동화, 규모에 따라 도구의 영향은 커진다.
- CI/CD 파이프라인 연동 가능 여부
- 팀원과 스크립트를 공유하고 버전관리할 수 있는지
- 대규모 분산 테스트를 지원하는지
- 조직 안에서 누가 테스트를 작성하고 실행하는지
따라서 결론은 다음과 같다.
지표를 읽는 눈 + 상황에 맞는 도구 선택
이 두 가지가 함께 있어야 실전에서 쓸 수 있는 성능 테스트 역량이 된다.
---
16. 핵심 정리
부하 테스트는
“서버가 언제 한계에 부딪히는지 보는 테스트”
만이 아니다.
더 정확히는
어디까지 안정적으로 처리할 수 있는지를 찾는 과정
이다.
기억해야 할 핵심 지표는 세 가지이다.
지표 의미 핵심 가치
| TPS | 처리량 | 최대 처리 용량 파악 |
| P99 | 지연 시간 | 실제 사용자 경험과 병목·장애 직전 신호 감지 |
| Error Rate | 실패율 | 한계 초과 시점 감지 |
마지막으로, 부하 테스트를 할 때는 다음 흐름을 기억하면 된다.
VU 증가
-> TPS 증가
-> TPS 정체
-> P99 Latency 증가
-> Error Rate 증가이 흐름에서 전환 구간을 찾는 것이 부하 테스트의 본질이다.
---
참고
- 예스24 랜섬웨어 장애 및 일부 서비스 재개 관련 보도: 서울경제, 2025-06-13, https://www.sedaily.com/NewsView/2GU253IY0Z
- 예스24 랜섬웨어 장애 및 일부 서비스 재개 관련 보도: 매경ECONOMY, 2025-06-13, https://www.mk.co.kr/news/business/11342167