운영 환경에서 장애를 분석할 때 가장 먼저 보는 것은 보통 로그다. 그런데 트래픽이 많은 서버에서는 여러 사용자의 요청 로그가 뒤섞여 출력된다.
회원 조회 시작
예약 생성 시작
회원 조회 완료
예약 생성 실패이 로그만 보면 어떤 요청에서 어떤 일이 일어났는지 추적하기 어렵다.
이 문제를 해결하기 위해 많이 사용하는 방식이 traceId를 로그마다 함께 남기는 것이다.
[9f31a2bc] 회원 조회 시작
[7ac91d02] 예약 생성 시작
[9f31a2bc] 회원 조회 완료
[7ac91d02] 예약 생성 실패Spring Boot에서는 이 구조를 보통 MDC와 Servlet Filter를 이용해서 구현한다.
프로젝트 구조
간단한 프로젝트 구조로 예시를 들어보자면 다음 두 파일이 핵심이다.
src/main/java/com/example/api-server/MdcLoggingFilter.java
src/main/resources/logback-spring.xmlMdcLoggingFilter는 요청마다 traceId를 만들고 MDC에 저장한다.
@Component
public class MdcLoggingFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
String traceId = UUID.randomUUID().toString().substring(0, 8);
MDC.put("traceId", traceId);
try {
chain.doFilter(request, response);
} finally {
MDC.clear();
}
}
}그리고 logback-spring.xml은 MDC에 들어 있는 traceId를 로그 패턴에 출력한다.
<pattern>
%d{yyyy-MM-dd HH:mm:ss.SSS} %highlight(%-5level)
%magenta([%X{traceId}])
%yellow([%thread])
%cyan(%logger{36}) : %msg%n
</pattern>여기서 핵심은 %X{traceId}다.
Logback에서 %X{key}는 현재 스레드의 MDC에서 해당 key 값을 꺼내 로그에 출력하라는 의미다.
즉, 연결 구조는 이렇게 된다.
logback-spring.xml은 누가 찾아서 적용할까?
MdcLoggingFilter가 logback-spring.xml을 직접 찾는 것은 아니다.
이 파일은 Spring Boot의 로깅 초기화 과정에서 자동으로 발견된다.
현재 프로젝트는 spring-boot-starter-webmvc를 사용하고 있다.
implementation 'org.springframework.boot:spring-boot-starter-webmvc'Spring Boot starter를 사용하면 기본 로깅 구현체로 Logback이 함께 구성된다. 애플리케이션이 시작되면 Spring Boot는 클래스패스 루트에서 다음과 같은 로깅 설정 파일을 찾는다.
logback-spring.xml
logback.xmlsrc/main/resources/logback-spring.xml은 빌드 후 클래스패스 루트로 복사된다.

그래서 별도의 코드 없이도 logback-spring.xml이 적용된다.
만약 다른 위치의 파일을 쓰고 싶다면 application.yaml 또는 실행 옵션에서 logging.config를 지정할 수 있다.
logging:
config: classpath:logging/logback-prod.xml또는 외부 파일을 지정할 수도 있다.
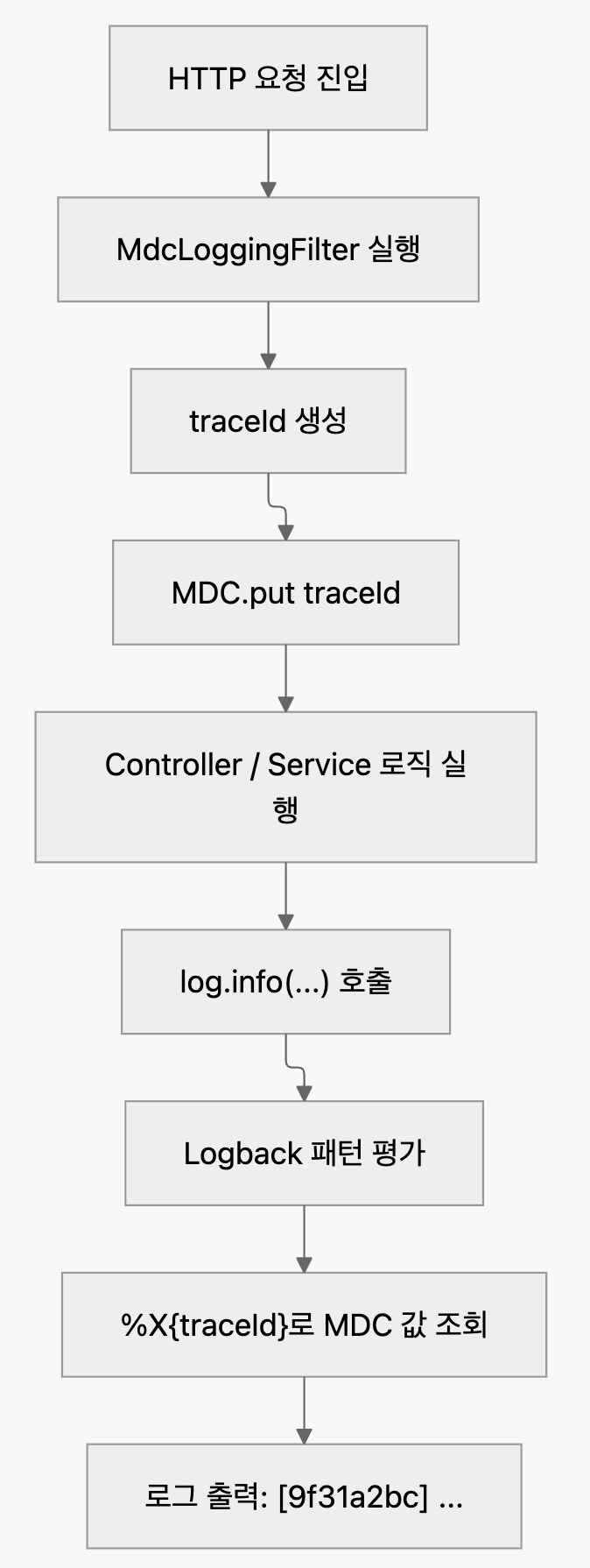
java -jar app.jar --logging.config=file:/app/config/logback-spring.xml요청 하나가 처리되는 전체 흐름
요청이 들어오면 전체 흐름은 다음과 같다.
예를 들어 Controller와 Service에서 로그를 찍는다고 해보자.
@RestController
@RequiredArgsConstructor
public class WaitingController {
private static final Logger log = LoggerFactory.getLogger(WaitingController.class);
private final WaitingService waitingService;
@PostMapping("/waiting")
public void createWaiting(@RequestBody WaitingRequest request) {
log.info("waiting request received");
waitingService.create(request);
}
}@Service
public class WaitingService {
private static final Logger log = LoggerFactory.getLogger(WaitingService.class);
public void create(WaitingRequest request) {
log.info("waiting create started");
log.info("waiting create completed");
}
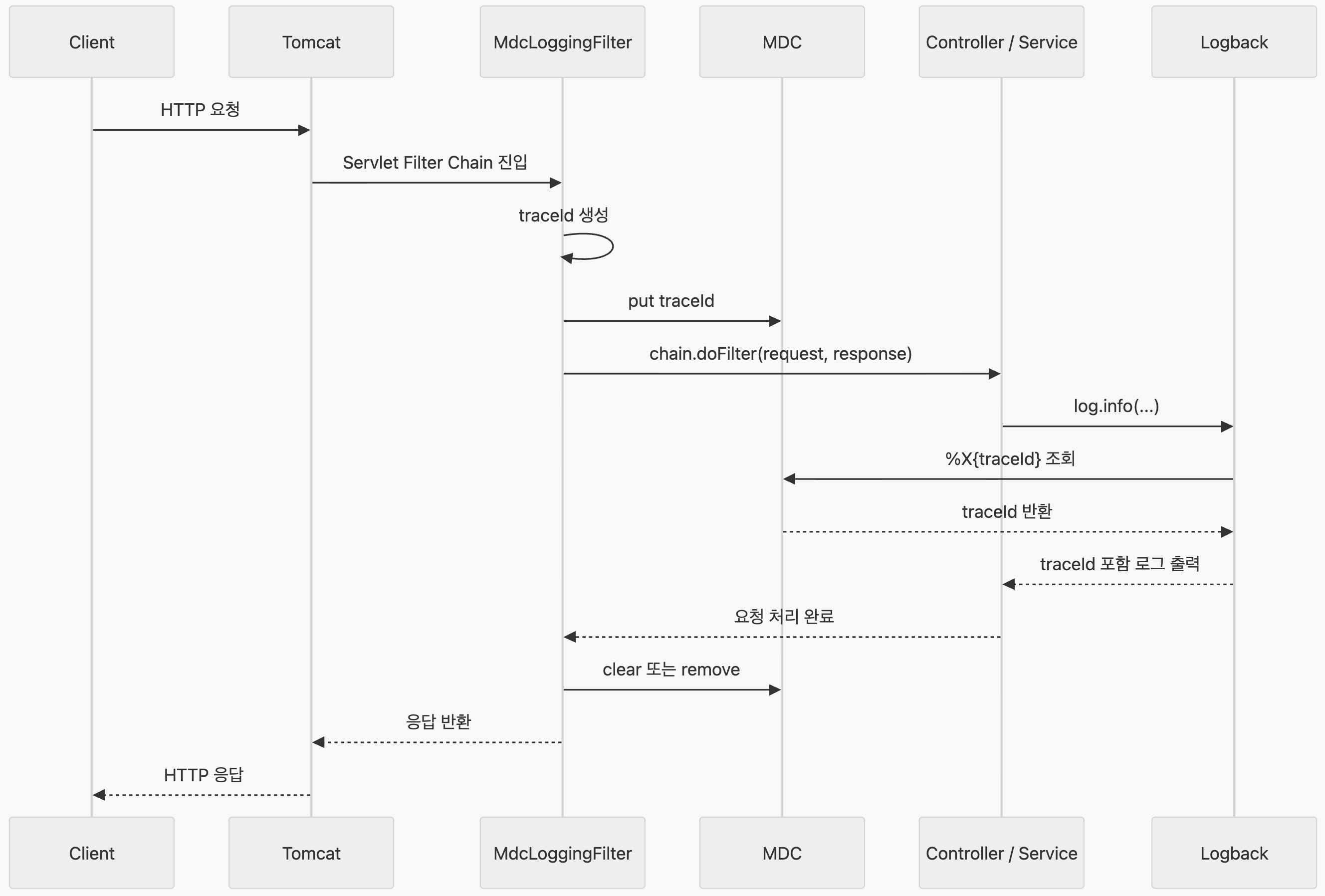
}요청 하나에 대해 다음처럼 같은 traceId가 찍힌다.
2026-05-19 20:10:01.123 INFO [9f31a2bc] [http-nio-8080-exec-1] WaitingController : waiting request received
2026-05-19 20:10:01.130 INFO [9f31a2bc] [http-nio-8080-exec-1] WaitingService : waiting create started
2026-05-19 20:10:01.145 INFO [9f31a2bc] [http-nio-8080-exec-1] WaitingService : waiting create completedMDC는 기본적으로 현재 스레드 기준으로 값을 저장한다.
그래서 같은 요청을 처리하는 동안 같은 스레드에서 찍히는 로그에는 같은 traceId가 붙는다.
왜 finally에서 MDC를 지워야 할까?
Servlet container의 요청 처리 스레드는 요청마다 새로 만들어지는 것이 아니다. Tomcat은 스레드 풀을 사용하고, 한 요청을 처리한 스레드가 다음 요청에도 재사용될 수 있다.
만약 MDC를 지우지 않으면 다음 요청 로그에 이전 요청의 traceId가 남을 수 있다.
try {
chain.doFilter(request, response);
} finally {
MDC.clear();
}운영 코드에서는 MDC.clear() 대신 특정 key만 제거하는 방식도 많이 쓴다.
finally {
MDC.remove("traceId");
}MDC.clear()는 현재 스레드의 MDC 값을 전부 지운다.
만약 다른 필터나 라이브러리가 userId, spanId, tenantId 같은 값을 MDC에 넣고 있다면 같이 지워질 수 있다.
그래서 운영 환경에서는 “내가 넣은 값만 제거한다”는 원칙이 더 안전하다.
운영 환경에서는 어떻게 구현할까?
학습용 구현에서는 요청마다 UUID를 새로 만들면 충분하다.
String traceId = UUID.randomUUID().toString().substring(0, 8);하지만 운영 환경에서는 보통 다음 요구사항이 추가된다.
- 클라이언트나 API Gateway가 보낸 traceId가 있으면 이어받는다.
- 없으면 서버에서 새로 만든다.
- 응답 헤더에도 traceId를 내려준다.
- MDC는 반드시 요청 종료 시 정리한다.
- 비동기 처리나 다른 스레드로 넘어가는 경우도 고려한다.
- 개인정보는 MDC에 넣지 않는다.
- 로그 수집 시스템에서 검색하기 좋은 형태로 출력한다.
운영 환경에서 traceId를 결정하는 흐름은 보통 다음과 같다.

조금 더 운영 친화적으로 만들면 다음과 같다.
@Component
public class MdcLoggingFilter extends OncePerRequestFilter {
private static final String TRACE_ID = "traceId";
private static final String TRACE_ID_HEADER = "X-Request-Id";
@Override
protected void doFilterInternal(
HttpServletRequest request,
HttpServletResponse response,
FilterChain filterChain
) throws ServletException, IOException {
String traceId = resolveTraceId(request);
MDC.put(TRACE_ID, traceId);
response.setHeader(TRACE_ID_HEADER, traceId);
try {
filterChain.doFilter(request, response);
} finally {
MDC.remove(TRACE_ID);
}
}
private String resolveTraceId(HttpServletRequest request) {
String traceId = request.getHeader(TRACE_ID_HEADER);
if (traceId == null || traceId.isBlank()) {
return UUID.randomUUID().toString();
}
return traceId;
}
}여기서는 Filter 대신 OncePerRequestFilter를 사용했다.
Spring Web 환경에서는 요청당 한 번만 실행되어야 하는 필터를 만들 때 OncePerRequestFilter가 더 명확하다.
Header를 이어받는 이유
운영 환경에서는 요청이 보통 한 서버에서 끝나지 않는다.
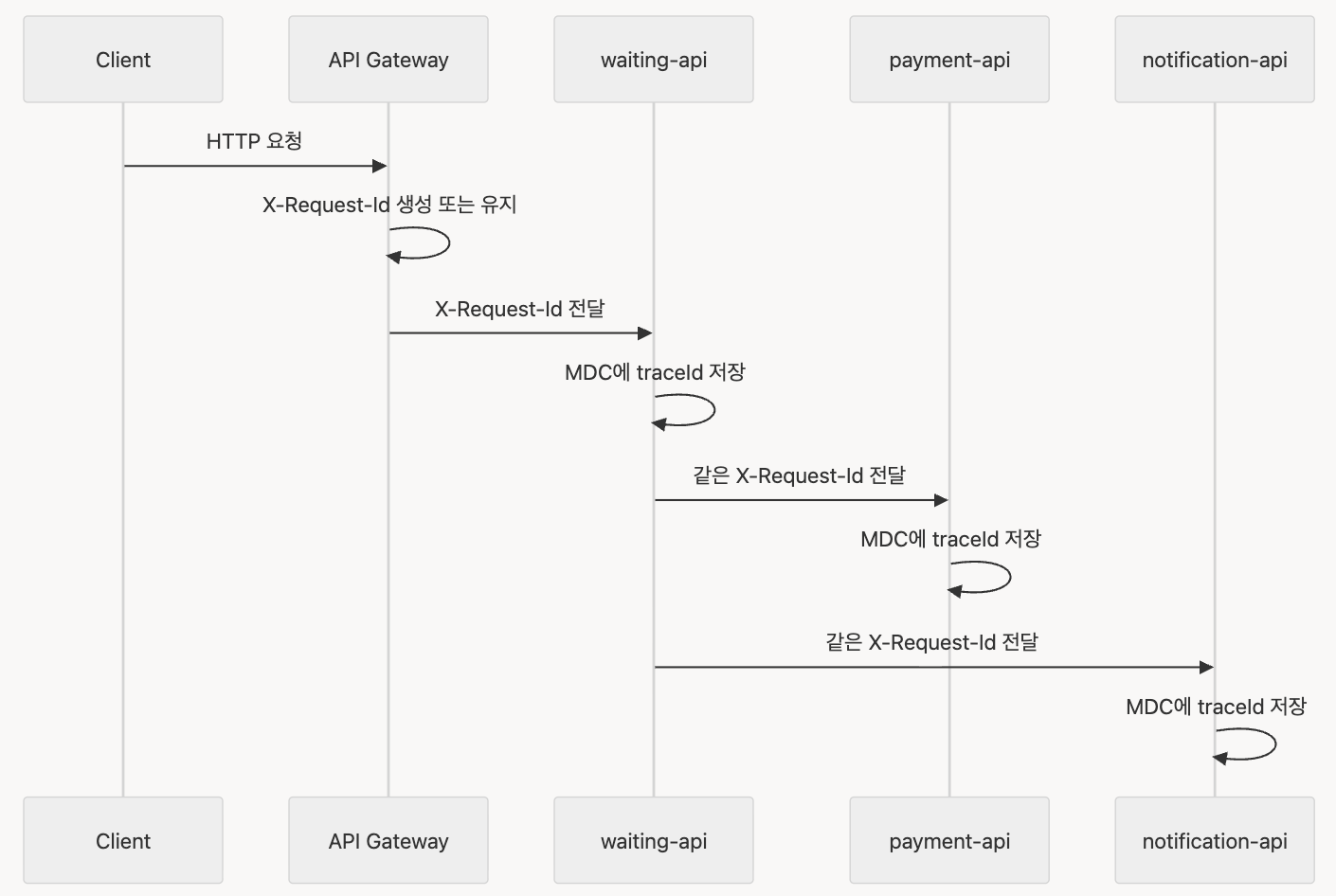
이때 waiting-api가 매번 새로운 traceId를 만들면 시스템 전체에서 하나의 요청을 추적하기 어렵다.
그래서 앞단에서 이미 X-Request-Id를 보냈다면 그대로 이어받는다.
Client Request Header
X-Request-Id: req-20260519-abcdwaiting-api 로그:
[req-20260519-abcd] waiting request receivedpayment-api 로그:
[req-20260519-abcd] payment request received이렇게 되면 로그 시스템에서 req-20260519-abcd 하나로 여러 서비스의 로그를 함께 검색할 수 있다.
logback 설정 예시
콘솔 로그만 사용한다면 현재처럼 단순한 패턴도 충분하다.
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>
%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level [%X{traceId}] [%thread] %logger{36} : %msg%n
</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
</root>
</configuration>운영 환경에서는 로그 수집 시스템과 연동하기 위해 JSON 로그를 쓰는 경우도 많다. 예를 들어 ELK, Loki, Datadog 같은 시스템에 로그를 보낼 때는 사람이 읽는 문자열보다 필드 기반 검색이 더 중요하다.
개념적으로는 이런 형태가 더 검색하기 좋다.
{
"timestamp": "2026-05-19T20:10:01.123+09:00",
"level": "INFO",
"traceId": "req-20260519-abcd",
"thread": "http-nio-8080-exec-1",
"logger": "com.hi.waiting_api.WaitingService",
"message": "waiting create completed"
}문자열 로그에서는 traceId가 본문 안에 섞여 있지만, JSON 로그에서는 traceId가 독립 필드가 된다.
운영 검색 관점에서는 이 차이가 꽤 크다.
Filter 순서도 중요하다
MDC 필터는 가능하면 요청 처리 초기에 실행되는 것이 좋다.
그래야 인증 필터, Controller, 예외 핸들러 등 뒤에서 찍히는 로그에 모두 traceId가 붙는다.
필터 순서를 도식으로 보면 다음과 같다.

필터 순서를 명시하고 싶다면 FilterRegistrationBean을 사용할 수 있다.
@Configuration
public class FilterConfig {
@Bean
public FilterRegistrationBean<MdcLoggingFilter> mdcLoggingFilterRegistration(
MdcLoggingFilter filter
) {
FilterRegistrationBean<MdcLoggingFilter> registration = new FilterRegistrationBean<>();
registration.setFilter(filter);
registration.setOrder(Ordered.HIGHEST_PRECEDENCE);
registration.addUrlPatterns("/*");
return registration;
}
}단, 이 방식을 쓸 때는 필터가 중복 등록되지 않도록 주의해야 한다.
@Component로 자동 등록하면서 동시에 FilterRegistrationBean으로도 등록하면 의도치 않게 두 번 실행될 수 있다.
운영 코드에서는 등록 방식을 하나로 정하는 것이 좋다.
비동기 처리에서의 주의점
MDC는 기본적으로 ThreadLocal 기반이다. 즉, 현재 스레드에 묶여 있다.
요청 스레드에서 로그를 찍으면 문제가 없다.

하지만 작업이 다른 스레드로 넘어가면 MDC가 자동으로 따라가지 않을 수 있다.
@Async
public void sendNotification() {
log.info("send notification");
}이 로그는 다른 스레드에서 실행될 수 있다.

그래서 비동기 작업, 스레드 풀, 이벤트 리스너, 메시지 큐 소비자에서는 별도 전파 전략이 필요하다. 예를 들면 TaskDecorator를 사용해 MDC context를 복사할 수 있다.
여기서 TaskDecorator는 static으로 존재하는 전역 객체가 아니다.
Spring이 제공하는 인터페이스이며, 스레드 풀에 작업이 제출될 때 Runnable을 한 번 감싸는 역할을 한다.
개념적으로는 다음과 같다.
public interface TaskDecorator {
Runnable decorate(Runnable runnable);
}즉, 원래 실행될 작업이 다음과 같이 있다면,
Runnable originalTask = () -> {
log.info("send notification");
};TaskDecorator는 이 작업을 바로 실행하지 않고, 앞뒤로 공통 로직이 붙은 새 Runnable로 감싼다.
Runnable decoratedTask = () -> {
// 실행 전 공통 작업
originalTask.run();
// 실행 후 공통 작업
};MDC 전파에서는 “실행 전 공통 작업”에 MDC.setContextMap(...)을 넣고, “실행 후 공통 작업”에 MDC.clear()를 넣는다.

중요한 점은 MDC.getCopyOfContextMap()이 실행되는 시점이다.
이 코드는 비동기 작업이 실제로 실행되는 작업 스레드에서 호출되면 안 된다.
작업 스레드로 넘어가기 전에, 즉 요청 스레드에 아직 MDC 값이 남아 있을 때 호출되어야 한다.
요청 스레드에서 복사해야 하는 값
MDC: traceId=abc123
작업 스레드에서 복사하려고 하면 이미 늦을 수 있는 값
MDC: empty그래서 TaskDecorator는 다음 순서로 동작한다.
- 요청 스레드에서 비동기 작업이 제출된다.
TaskDecorator가 현재 요청 스레드의 MDC 값을 복사한다.- 복사한 값을 내부에 들고 있는 새
Runnable을 반환한다. - 스레드 풀은 원본
Runnable이 아니라 감싸진Runnable을 실행한다. - 작업 스레드에서 실행 직전에 MDC 값을 복원한다.
- 실제 비동기 로직을 실행한다.
- 실행이 끝나면 작업 스레드의 MDC를 정리한다.
@Bean
public TaskDecorator mdcTaskDecorator() {
return runnable -> {
Map<String, String> contextMap = MDC.getCopyOfContextMap();
return () -> {
if (contextMap != null) {
MDC.setContextMap(contextMap);
}
try {
runnable.run();
} finally {
MDC.clear();
}
};
};
}이 코드에서 바깥쪽 람다는 요청 스레드에서 실행된다고 이해하면 된다.
return runnable -> {
Map<String, String> contextMap = MDC.getCopyOfContextMap();
...
};반면 안쪽 람다는 실제 비동기 작업 스레드에서 실행된다.
return () -> {
MDC.setContextMap(contextMap);
runnable.run();
};이 구분이 중요하다. 바깥쪽에서 MDC 값을 복사해두고, 안쪽에서 그 값을 복원하는 구조이기 때문이다.
다만 TaskDecorator Bean을 선언하는 것만으로 모든 비동기 작업에 자동 적용되는 것은 아니다.
ThreadPoolTaskExecutor에 직접 연결해야 한다.
@Configuration
@EnableAsync
public class AsyncConfig {
@Bean
public TaskDecorator mdcTaskDecorator() {
return runnable -> {
Map<String, String> contextMap = MDC.getCopyOfContextMap();
return () -> {
if (contextMap != null) {
MDC.setContextMap(contextMap);
}
try {
runnable.run();
} finally {
MDC.clear();
}
};
};
}
@Bean
public ThreadPoolTaskExecutor applicationTaskExecutor(TaskDecorator mdcTaskDecorator) {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10);
executor.setMaxPoolSize(50);
executor.setQueueCapacity(100);
executor.setThreadNamePrefix("async-");
executor.setTaskDecorator(mdcTaskDecorator);
executor.initialize();
return executor;
}
}이 설정을 ThreadPoolTaskExecutor에 연결하면 비동기 스레드에서도 기존 MDC 값을 사용할 수 있다.
여기서 MDC의 메서드가 static 형태로 보이기 때문에 헷갈릴 수 있다.
MDC.put("traceId", traceId);
MDC.getCopyOfContextMap();
MDC.setContextMap(contextMap);
MDC.clear();하지만 값이 애플리케이션 전체에 하나만 저장되는 것은 아니다.
SLF4J의 MDC는 static 메서드를 통해 접근하지만, 내부적으로는 현재 스레드에 묶인 context를 다룬다고 보면 된다.
그래서 요청 스레드와 작업 스레드가 달라지면 MDC 값도 자동으로 공유되지 않는다.
정리하면 다음과 같다.
TaskDecorator
- Spring이 제공하는 인터페이스다.
- static 객체가 아니다.
- Runnable 실행 전후에 공통 처리를 끼워 넣는 hook이다.
- MDC 전파에서는 요청 스레드의 MDC를 복사해 작업 스레드에 복원하는 데 사용한다.
- Bean으로 만들기만 해서는 부족하고 ThreadPoolTaskExecutor에 연결해야 한다.
MDC
- static 메서드로 접근한다.
- 하지만 값은 전역 하나가 아니라 스레드별 context에 저장된다고 이해하면 된다.
- 그래서 비동기 스레드로 넘어가면 별도 전파가 필요하다.MDC에 넣으면 안 되는 값
운영 환경에서는 MDC가 로그로 남는다는 점을 항상 기억해야 한다. 다음 값들은 MDC에 넣지 않는 것이 좋다.
비밀번호
토큰
주민등록번호
카드번호
민감한 개인정보
너무 긴 요청 본문대신 운영에서 자주 넣는 값은 다음 정도다.
traceId
spanId
requestId
userId 또는 memberId
clientIp
httpMethod
requestUriuserId도 개인정보 정책에 따라 주의가 필요하다.
외부에 노출될 가능성이 있는 로그라면 내부 식별자 또는 마스킹된 값을 사용하는 것이 좋다.
정리
MDC 로깅 필터의 핵심은 단순하다.

현재 프로젝트에서는 MdcLoggingFilter가 traceId를 만들고, logback-spring.xml이 그 값을 출력한다.
두 파일이 직접 연결되는 것이 아니라 MDC라는 저장소와 traceId라는 key를 통해 느슨하게 연결된다.
학습용 구현에서는 요청마다 UUID를 생성하는 방식으로 충분하다. 운영 환경에서는 헤더 기반 traceId 전파, 응답 헤더 추가, 필터 순서, 비동기 MDC 전파, 개인정보 보호, JSON 로그 구조까지 함께 고려해야 한다.
결국 MDC 로깅의 목적은 “로그를 예쁘게 출력하는 것”이 아니라, 장애 상황에서 하나의 요청 흐름을 빠르게 복원할 수 있게 만드는 것이다.
참고
- Spring Boot Logging 공식 문서: https://docs.spring.io/spring-boot/4.0-SNAPSHOT/reference/features/logging.html
- Spring Boot Logback 설정 문서: https://docs.spring.io/spring-boot/4.0-SNAPSHOT/how-to/logging.html

